
The Strange Loop conference describes itself as “a multi-disciplinary conference that brings together the developers and thinkers building tomorrow’s technology in fields such as emerging languages, alternative databases, concurrency, distributed systems, security, and the web.” However, as the presentation summaries below suggest, the conference is even more expansive than that.
It’s a unique event in that it doesn’t focus on traditional talks in a single field of computer science, such as machine learning, as most conferences do. Rather, speakers present on projects across a wide and often fascinating variety of areas. It is, as the organizers describe it, “technology stew.”
Strange Loop is quirky and fun. It’s about building connections with new potential colleagues and collaborators–not to mention that it features an incredible opening-night party at St. Louis’s City Museum, which features a giant jungle gym for adults (with the world’s largest indoor slide), plus an amazing youth circus program.
Two Sigma has long embraced the notion of “technology stew,” which is one reason why we have two Hacker Labs, where employees can spend time on personal technology projects, and why we hold events like human vs. machine air hockey contests for our engineers, data scientists, and others. We’ve found that when people have leeway to do something creative, a lot of innovation can result–and some of that finds its way back into our “day jobs.”

Two Sigma sponsored Strange Loop 2019, as it has several times in the past. We also sponsored the 2019 Papers We Love conference (PWLConf 2019), as we have since its inception, which was held a day before the start of Strange Loop in St. Louis. We similarly value the opportunity PWL gives engineers and others to highlight research that has particularly inspired them over the course of their careers.
Below, we summarize some of the most memorable papers, talks, and presentations from both Strange Loop and Papers We Love.
Special thanks to Ben Linsay, Rachel Malbin, Rhys Ulerich, Tony Walker, and John Zeringue for their help preparing this article.
Strange Loop 2019
Keynotes
How to Teach Programming – Video
Felienne Hermans, head of the Programming Education Research Lab (PERL), associate professor at the Leiden Institute of Advanced Computer Science at Leiden University
Dr. Hermans presented her research on how to teach programming most effectively. According to Hermans, historically the teaching of computer science has been based on Piaget’s influence on Seymour Papert. Their method of constructivism states that “by explaining something, you take away the opportunity for a child to discover it.” Thus, they would argue that teachers shouldn’t explain much. Hermans counters that argument with the method of explanation and practice (e.g., phonics), as demonstrated in the meta-study “Why minimal guidance does not work.” She also notes that learning is more effective when people are not cognitively loaded. Instead, simplify and focus the setting on the aspects you want learners to retain.
One of the more interesting revelations for a non-programmer present was that Dr. Hermans considers Excel to be a programming language. She also hand-draws her slides, which certainly helped the message stick better than the standard clip art does. The call to action from this talk was to spark a pedagogical debate in how to teach programming.
(Incidentally, programmers may be interested in taking her survey, How do you see these programming languages? at bit.ly/pl-views.)
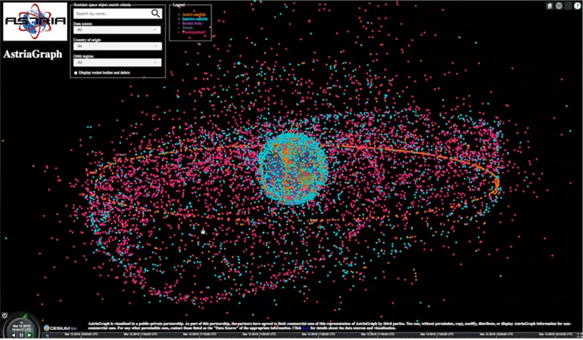
ASTRIAGraph: Monitoring Global Traffic in Space!
Moriba Jah, associate professor, University of Texas at Austin
Professor Jah gave a live demonstration of ASTRIAGraph, a Neo4j-based system for tracking orbital satellites and debris. Over the next five years, humanity plans to launch as many satellites as our species has to date. With orbit becoming increasingly crowded, establishing “rules of the road” and coordinating among various private- and public-sector groups has become increasingly important. The heart of this challenge requires ingesting disparate, sometimes conflicting, data sources and using that collection of information for physics-informed predictions.
How Computers Misunderstand the World
Meredith Broussard, assistant professor, Arthur L. Carter Journalism Institute of New York University
Professor Broussard focuses on the ethics of artificial intelligence and the ways journalists use data in investigative articles and for social good. Her recent book, Artificial Unintelligence: How Computers Misunderstand the World, discusses how people embed their own unconscious biases in technology, which she terms “technochauvism.”
Broussard touched on embedded bias in both words and algorithms (she references Lipstick on a Pig: Debiasing Methods Cover up Systematic Gender Biases in Word Embeddings But do not Remove Them (from NAACL 2019), Machine Bias from Julia Angwin at ProPublica, Algorithms of Oppression by Safiya Umoja Noble, and many others). She also encouraged the audience to be linguistically precise when describing processes as being “automated,” when in reality they are being performed by human ghost workers.
Summing up her talk, she cited a well-known quote: “Not everything that counts can be counted, and not everything that can be counted counts.” With that in mind, Broussard encouraged attendees to be conscientious when relying on automation and challenged the audience to contemplate how to use technology with intentionality, to help make the world as it should be.
Closing Keynote
Recording Artist Imogen Heap
Where else but Strange Loop, as one attendee noted, can you see a conference keynote on music, fiber-optic gloves, blockchain, smart contracts, and performance art?
Singer-songwriter Imogen Heap demonstrated a pair of mi.mu gloves she co-developed that contain sensors and microphones, enabling her to use physical gestures to create elaborate music in real-time. (Can we be the first to say: Coolest. Gloves. Ever.) Heap drew inspiration from Elly Jessop’s VAMP gloves, which she first saw at MIT’s Media Lab. Watching the artist create songs was reminiscent of watching someone play a theremin, but the process is far more interactive, and the results far richer.
While many attempts have been made to integrate technology into music, the mi.mu gloves would seem to represent the state of the art. In this case, having a musician drive development led to a tool with a very natural workflow, rather than one that forces a musician to adapt to engineering constraints. With a pinch of the fingers, Heap is able to grab a note that she sings and start looping it using another slight gesture. She layers these elements with drumming samples (also triggered by gestures) and finally by singing lyrics on top of it all. Her most popular song on Spotify, “Hide and Seek,” exemplifies the beauty of this layering.
In her talk, she described how her friendships with technologists have also led her to research the possibilities of blockchain payment for music royalties, which she pioneered with her release of the song “Tiny Human” on a distributed ledger platform she developed called Mycelia. She advocated for musicians controlling their digital identities by linking songs to relevant related data, such as the identities of other musicians playing on a song, through the Creative Passport.
New Ideas and Advances
Better Spotify playlists through discrete optimization – video
Cedric Hurst, Founder & Principal of Spantree
This talk explored methods for optimizing the order of Spotify playlists for maximum continuity, as defined by the speaker, a musician and former DJ. For example, he posits that consecutive songs should have pleasant key changes, similar tempos, similar styles, etc.
Spotify’s Web API seems to have a lot of really interesting data to play with for free (which, incidentally, could make it great for hack day projects or demos). Hurst used OptaPlanner (an open source constraint solver) to do his optimization, and Drools (a Business Rules Management System solution) to specify the constraints. Both of these are interesting choices, because they provide an object-oriented interface into discrete optimization.
After explaining the techniques and technologies he used, Hurst showed off a public demo (http://spotfire.io). He talked briefly about how he built the site, explaining how he ran the optimizations “serverless” (AWS Lambda), to avoid overloading the web server.
New programming constructs for probabilistic AI – video
Marco Cusumano-Towner, MIT Probabilistic Computing Project
MIT’s probcomp lab was out in force at Strange Loop, advocating for “probabilistic programming,” which aims to “engineer computing systems with simple forms of perception and judgment.” Most of it seems to be built on a tool called Gen that researchers wrote in Julia. Basically, a researcher just writes a simulator to generate random states, and the Gen platform is able to use this to make predictions from partial-known information. It can also incorporate heuristics. Based on the lab’s code samples, Julia seems to have much more powerful metaprogramming than Python. Finally, there’s a neat demo in the video about path prediction only having simulated how to generate a path.
Voice Driven Development: Who needs a keyboard anyway? – video
Emily Shea,Senior Software Engineer, Fastly
The presenter had developed severe repetitive-stress injury and tried various fixes: braces, yoga, medication, etc., but to no avail. In this talk, she referenced a video of someone using voice recognition in Windows Vista to write Perl ( her primary language), and she wanted to see how this could work with today’s tech.
Her stack consists of a decent microphone, Dragon Dictate (on the Mac) and open-source software called Talon. Talon requires a dictation engine (currently Dragon, but they’re working on an open source engine). Her talk featured great demos of the solution she built–especially the use of a phonetic alphabet that differs from the standard NATO alphabet, in that all words are single syllables (unlike “al-pha” or “bra-vo”), which keeps things fast. She highlighted some important challenges in building this kind of tech, including a steep learning curve, the immaturity of the space overall, and the fact that most people use very bespoke setups and scripts.
Probabilistic scripts for automating common-sense tasks – video
Alexander Lew, MIT Probabilistic Computing Project
This very thought-provoking talk consisted mostly of a demo showing how one could encode “common sense,” like city size or average rent, into a probabilistic programming system and automatically clean a data set. Though fascinating, it’s hard to say when or if techniques like this will become practical or mainstream. Still, it’s an idea that makes a lot of sense. Why handle edge cases by trial and error, when you can teach the computer which fix is most likely correct, and then let it do the heavy lifting on its own?
Better Integration Tests for Performance Monitoring – video
Maude Lemaire, Slack
The speaker, a former front-end, and now back-end, engineer at Slack, works mostly toward making the lives of the company’s devs more productive. Her team deals with upgrades to the language stack (written in HHVM/Hacklang), stewardship of core libraries (logging/metrics gathering/DB access), linters, unit/integration test frameworks, and so on.
Their typical cycle for building new features is to find an existing API, then find relevant code, add some new ”’if”’ statements, then rinse and repeat. They typically ship ~100 times per day, with little visibility into the work’s greater impact on the Slack app.
Her team’s remit was to build something to find all performance regressions before code is merged (they named this solution “slerf”). The first priority was to protect APIs, so they identified the top 50 where customers are mostly likely to see regression (by usage). Next, they built a minimum viable product using existing infrastructure with a focus on counting DB and memcache queries per operation/endpoint. They did this because most performance problems centered around data-fetching of some kind. The team decided to discard looking at timing data, as their test/dev infra was flaky enough that doing so wouldn’t have been useful. Eventually they’d run tests/counts against old/new environments, and compare DB/memcache counts; it was alarming when numbers would change.
There were challenges with false-positives and flakiness in tests, but the new system has helped Slack engineers find big issues before release. Among Lemaire’s key takeaways were to build from what you have and to gate responsibly (if the test can block merges, think about what that interaction looks like with your developers).
Zipline – A Declarative Feature Engineering Library – video
Nikhil Simha, Airbnb
In a particularly interesting talk, an Airbnb engineer described Zipline, the company’s tool for managing model lifecycle. It’s specifically tailored to time-series models, and it’s configured declaratively, using highly optimized algorithms.
Features (data) and models (functions over data) are served through different systems. The feature store is similar to our Feature Catalog, although it focuses more on feature generation and providing a common data access layer. The model server evaluates trained models for applications across the company.
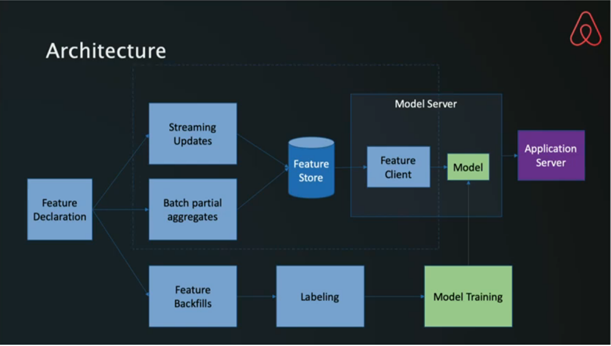
Model training and retraining is automated as part of Zipline. After a model is defined, the system automatically trains and deploys it. Retraining is also performed automatically, although the updated model must be manually redeployed.
Interesting parts of the lifecycle that were not covered in the talk include measuring model performance and what, if any, limits there are on the modeling techniques that the system supports. The presenter indicated that the system would be open sourced and a paper was likely forthcoming.
Fun at the Intersection of Art & Tech
The Idea Becomes a Machine That Makes the Art That Makes a Machine That Makes the Art (video) was a fascinating investigation into the intersection of machine learning, art, and philosophy. The project, by Prompt And Pleasant’s Christine Stavridis and Jonathan King, began with a question the conceptual artist Sol LeWitt once posed: Which constitutes art, the underlying idea, or the execution of that idea? He famously explored this question by devising instruction sets for artworks and having assistants carry them out–often with beautiful results.
Stavridis and King expanded on this concept by building several machine learning algorithms that produced new instructions and executions derived from a corpus of LeWitt’s originals.
Ultimately, the project evolved into an interesting analysis of what it means to be a collaborator with an artist like Sol LeWitt (who’s now deceased, but whose instructions live on). In addition, this project yielded an interesting proposal into one potential path for art conservation: using machine learning to model an artist’s techniques for use when restoring works long after the original artist no longer can.
Stavridis and King also point to other work on implementing ML in an artistically meaningful way, including:
- Sougwen Chung, Mechanical Operations, 2018
- Tom White, Treachery of ImageNet, 2017
- Holly Herndon, Mat Dryhurst, Jules La Place, Spawn
- Memo Akten, Learning to See, 2019
In Can Androids Conceive of Electric Sheep (video), Kwame Thomison tackled the problem of approximating the human creative process in designing an android artist. Most interesting were his descents into the uncanny valley and his many attempts to avoid this eerie simulation. (Speaking of the uncanny valley and AI-powered art, check out deeply artificial tree, which Thomison references in his talk.) Though he acknowledged that encoding human creativity was probably intractable, he decided to “see how far [he] could go.” The project is ongoing, but it was impressive to watch his investigation progress from photo-based line-rendering to an animated human model painting on a canvas, and finally to an algorithm making artistic choices and exercising its own version of “creativity.”
How not to read the room: Creating wearables with ML (video) covered a project that Stephanie Nemeth–a self-described introvert–devised to use wearables and machine learning to encourage her to be more outgoing (while learning some new programming skills). In the talk, she explains the evolution of an LED necklace powered by ML, running on a Raspberry Pi, and using Node.js and Tensorflow.js. The necklace links to an Arduino and features a camera and light-up BlinkyTiles to prompt her to socialize in a particularly original way. When the necklace’s camera “sees” that she’s not interacting with someone else, it plays an annoying noise. When she is speaking with someone, however, the necklace lights up, “revealing its magic.” Her main LED structure came from BlinkinLabs, which Two Sigma has partnered with in the past to create an open source 8×8 Blinky.
Tweet My Wedding Dress (video) tells the tale of a programmer’s first journey into the joys and frustrations of wearables. A color-changing, tweet-controlled bunny at EMF Camp inspired Jo Franchetti to adopt the technology for her wedding dress, despite having no background in making wearable tech.
Over the course of the two-year project, she learned the delights and pitfalls of microcontrollers and LEDs. Her finished product used an Adafruit Feather Huzzah (ESP8266 board package) and some knockoff NeoPixels hot-glued into a dress and soldered together. Once she’d set up a Twitter account for the dress and hooked into the API, her friends and family could control the dress’s color in real time via tweet! The result was beautiful, but unfortunately, like many wearable projects, it broke on the way to the event. Joys and frustrations, indeed.
Papers We Love Conference 2019: Three Highlights
Shriram Krishnamurthi, Vice President for Programming Languages at Brown University, opened the Papers We Love Conference with On The Expressive Power of Programming Languages, “the most stunning paper [he has] ever read; it’s like the poem that never leaves your soul.” Krishnamurthi brought that sense of awe across and showed the audience how–mathematically–you can determine when a new piece of syntax makes a programming language more expressive. He also brought nuance to his talk, making it clear that the paper presented a deeply academic view of expressivity. He finished the talk by arguing that the formal expressive power of a feature absolutely isn’t the only thing language designers should consider, although it should inform their choices. Un-expressive features matter, too.
Giulia Fanti, an assistant professor of ECE at CMU presented on her research on Privacy Vulnerabilities in the Peer-to-Peer Network of Cryptocurrencies. She and her team are focused on how bitcoin users can be de-anonymized with public data. This paper focuses on a simple question: how effective are the obfuscation techniques used by bitcoin? Her team graphed bitcoin transactions, and managed to tie IP address to public keys for a large number of users. When bitcoin tried to address this with a protocol shift, Fanti determined that it had minimal impact. She ended by presenting the Dandelion Protocol, which takes advantage of the properties of the bitcoin graph to obfuscate identities much more effectively. It’s currently seeing real-world use and is being integrated into bitcoin core.
Research fellow at Cambridge University’s Department of Computer Science and Technology Heidi Howard presented her thesis, Distributed consensus revised, and follow-up paper, A Generalized Solution to Distributed Consensus. The unifying theme of these papers is that Paxos isn’t actually as narrow or complex as it’s made out to be; Howard argues that much of its subtlety comes from the original formalization by Lamport. Her talk goes through the formalization she derived by making state immutable, and generalizes over Paxos, Fast Paxos, Flexible Paxos, and more. The talk is catnip for anyone interested in distributed systems.