
Dynamic resource allocation in compute clusters is a way to provision compute resources to applications based on their current demands. A dynamic approach to resource allocation is more efficient than a static approach as it allows for resource sharing. At Two Sigma, most of our compute resources are dynamically allocated to applications. Like many cluster operators, we want to minimize task latency and maximize task throughput under heavy load. This blog introduces Cook – our fair preemptive resource scheduler for compute clusters.
Interactive, batch, and fairness
A task is a unit of compute that runs on a machine in the cluster and consumes a certain amount of resources, i.e., CPU, memory, etc. A job is a set of tasks that accomplish a single goal. Different kinds of jobs have different requirements for throughput and latency. Just like processes in operating system are commonly divided into interactive (foreground) and batch (background) categories, jobs in our environment have very similar characteristics. There are interactive jobs (small tasks that users run to get immediate feedback), and there are batch jobs (overnight or even multi-day tasks that users use to cover large ranges of data). For the former, latency is more important, and for the latter, throughput is. Furthermore, we believe that low latency for interactive jobs is usually more important than high throughput for batch jobs, because human time is expensive.
We use fairness to champion this belief. The idea is simple – resources should be given first to users that are currently using fewer of them. In this way, naturally interactive jobs will be prioritized because they use fewer resources. However, what if there are only batch jobs to run? If we give all of the available resources to these batch jobs, then we will have no resources for interactive jobs that appear before resources are freed; and if we hold resources for interactive jobs, we will waste those resources if the interactive jobs don’t show up. Without a reliable model to predict future workloads, we are in a quandary.
Preemption
We use preemption to solve this problem. Preemption means aborting a task and reclaiming its resources for another, more important task. The reason preemption is useful is that it is a fast way to recover resources if we make a decision earlier that no longer makes sense. With preemption, we can give all available resources to batch jobs, and if interactive jobs arrive, we can preempt some batch tasks and schedule interactive ones. The cost of this preemption is that we lose all the computation already completed for the tasks that we preempt. (Most of our jobs don’t support checkpointing.)
The next question is how to decide if one task is more important than another. In general, it is difficult to say user A’s tasks are more important than user B’s. However, it is easy to understand the relative importance among tasks for a single user. Once we know the importance of each user’s tasks alone, we can apply the principle of fairness to define their global importance – assuming tasks use same amount of resources, the most important tasks of each user are of the same importance, the second most important tasks of each user are of the same importance, so on and so forth. In practice, tasks are normalized by their resource usage.
To formalize this idea, we introduce a concept known as Cumulative Resource Share (CRS).
Assuming there is a total ordering among tasks for each user, where > means ‘more important than,’ we define the CRS of a task t to be the sum of all tasks of the same user that are greater than or equal to t (again, by the user’s declared relative importance), divided by the total cluster resources.
In other words:
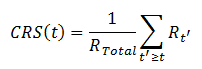
With that, we can use the CRS of a task to decide its importance relative to other tasks, and preempt if:
![]()
δ is the tolerance constant, i.e. how much unfairness we are willing to tolerate.
In Cook, we have extended CRS to support (1) per user weight, and (2) multiple resource types, like memory and CPUs.
Benchmark
Before releasing this in production, we wrote a simulator for our scheduler, Cook, and ran a 7 day production trace to evaluate the preemption algorithm. We compared the scheduler with and without preemption.
As mentioned earlier, the two things we are interested are latency and throughput.
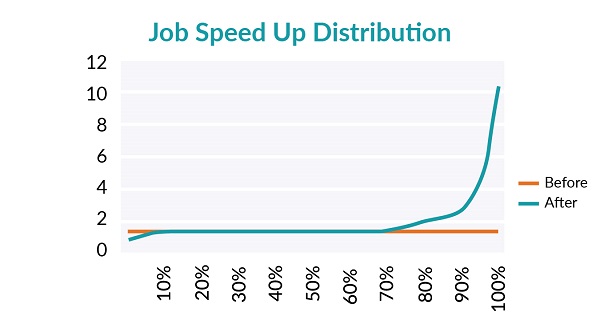
First, we use speed up, particularly for interactive jobs, to measure latency. We measured the simulated elapsed time between submission and completion for each job, and divided the time with preemption by the time without, and this ratio we named “Speed Up”. Figure 1 shows all tasks ranked by their speed up; 30% of jobs sped up from preemption, and 10% slowed down from it. More importantly, the 30% that sped up are interactive jobs, and the 10% that slowed down are batch jobs. Therefore preemption reduces latency for jobs which benefit most from lower latency.
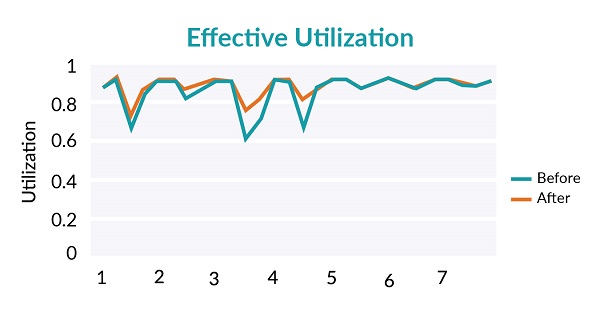
Second, we use effective cluster utilization to measure task throughput. The word “effective” means that we only count tasks that are not preempted: if a task runs for a while and is then preempted, the time it was running doesn’t count toward utilization, only after it is retried and runs to completion do we count that last run toward utilization. Figure 2 shows effective utilization with and without preemption. Effective utilization with preemption is lower, but the difference in average utilization is < 2%. We consider it a good tradeoff for the latency improvement. An interesting feature of the shape of utilization is that reduced utilization happens most during the night, where some batch jobs didn’t finish before users come to the office and launch interactive jobs.
Conclusion
This blog shows how we use preemption to achieve low latency and high throughput in our cluster. Cook has been running in production at Two Sigma for the past one and a half years. It is also a Two Sigma open source project. This work was also presented at MesosCon 2015, which is a more detailed illustration of this blog.