
Recent machine learning breakthroughs such as ChatGPT have showcased the apparent intuitive prowess of large language models (LLMs). However, despite their clearly transformative potential, LLMs are not always the best fit for every AI challenge. Indeed, non-LLM techniques will remain relevant within the field for the foreseeable future.
Central to machine learning’s rapid evolution is the crucial role of human intuition. Even with the advanced complexity and capabilities of LLMs and other machine learning models, their effectiveness ultimately relies on the nuanced understanding and intuitive insights of the data scientists who develop and use them.
A primary challenge in machine learning tasks is the selection of appropriate data, which, combined with the right algorithm, can lead to effective solutions. Frequently, issues arise either from the quality of data or the initial conceptualization of the task by researchers. In these instances, human intuition is vital, helping to assess whether the available data can support the creation of a reliable and robust machine learning model that can make decisions and act effectively on behalf of humans.
This article delves into nine common scenarios where the intuitive judgment of skilled practitioners is crucial for successfully applying machine learning—or deciding against its use. As we examine these examples, it becomes clear that despite advancements in machine learning technology, the intuitive input of human experts remains indispensable.
1. When a problem is (definitely) not a machine learning problem
The circumstances under which machine learning will (and must) fail are diverse, but, as mentioned above, they usually boil down to the data—even when there’s a lot of it—ultimately not having “what it takes” for a model to learn successfully.
Academic work can often hide in the abstract realm of I.I.D. assumptions (a blanket check that the data is independent and identically distributed) that the real world tends to not obey.
For example, if you only have data on homes for sale in New York City, using that dataset to predict home prices upstate, in Albany, is likely to fail. While the two cities may be in roughly the same geographical area, they are in many ways worlds apart.
Even if you had 10 years’ worth of data for Albany itself, the economic situation there would have changed significantly over that timeframe. Real-world circumstances are still not “close” enough to what’s represented in the data to build a viable machine learning model.
In such cases, the best course of action would be to realize that machine learning is likely NOT the sole answer, and to look for solutions elsewhere.
2. When a problem is (probably) not a machine learning problem
Sometimes all the data in the world is simply not enough. A non-exhaustive list of reasons why includes:
There are things neither you nor the data have ever seen before
In some cases, there is no appropriate data from which to learn. Elections, natural disasters, and other idiosyncratic events are examples of the past not necessarily providing a good blueprint for the future. In such situations, events exactly like them have literally never happened before. The task of forecasting such events is probably better performed by human subject-matter experts using a large dose of experience and intuition.
The effective size of the dataset is much smaller than you think
In other cases, the amount of data you have turns out to be irrelevant; what matters is the level of analysis on which the data will allow you to act.
During the winter of 2017-18, for example, the NYC Housing Authority reported that up to 80% of its approximately 1,435,000 apartments had experienced heating outages. Given that each apartment represents an array of relevant information (tenant demographics, usage patterns, etc.) this would seem like a perfect scenario for building a model that can predict the occurrence of heating outages.
It turns out that outages don’t actually happen at the apartment level. Rather, 100 or so aging boilers each heat entire buildings, so the effective size of the dataset to learn from is not 1,435,000 rows, but rather ~100.
There is no signal in the data you have
Lack of signal can have many causes. In the previous case, the apartment-level data about heating usage and demographics simply did not contain either root causes or early warning symptoms.
Even if symptoms are available, they may not have enough “variability” to be useful for a machine learning model. For example, researchers have tried to create an early-warning metric that would predict crop loss in major agricultural regions, such as in rural Africa. In one attempt that involved a year’s worth of satellite images and ground surveys from Malawi, the country’s small size and relatively homogenous annual weather conditions made creating a reliable, localized predictive model nearly impossible.
In other cases, the limiting factor is not in the variability or relevance of the available features, but the simple fact that the task is inherently very hard to predict.
This can certainly be the case regarding movements in financial markets. There is an inherent tradeoff between the amount of data required for a good model, the number of features that can be made available to the model, and the amount of signal in the data. With a strong signal, one can build models on few instances with a relatively large set of features. But when the signal is low, one either needs a lot more data or else has to dramatically reduce the number of features.
The problem is causal; your data may not be
Great caution is also crucial when a prediction might include the effects of the action you are deciding to take. At that moment you are crossing the chasm between correlation and causation.
It is one task to predict earnings surprises, for instance: no matter what a researcher predicts or does, it is unlikely to affect the probability of a surprise. But building a trade execution model could be a very different story, since a large enough transaction might itself affect the price of a financial instrument. Predicting, in a given market state, which strategy is likely to have the lowest cost is a causal question and requires experimentation. Sometimes predicting effects accurately may be possible; sometimes not.
There is another category when your model is unlikely to do better than historical averages: examples are traffic accidents in NYC (model might “explain” but not predict).
3. When you need to find for nails but all you have is a hammer
The prospects are not always bleak, however. On occasion, human intuition can find creative solutions around the data’s inherent limitations—or warn us that while a result looks valid, in fact it is not.
On occasion, human intuition can find creative solutions around the data’s inherent limitations—or warn us that while a result looks valid, in fact it is not.
Supervised modeling has a huge advantage over many other ML approaches. It is objectively possible to evaluate the performance of a model against some ground truth (did the model correctly identify a photo of a cat?). As a result, one can also clearly recognize failure. In fact, even LLMs utilize this idea during training: all they are learning to do is to predict the next word in a sentence.
However, that ground truth of interest is sometimes hard to come by. Consider the case of a company trying to predict the total “best case scenario” sales opportunity (or “customer wallet,” in industry jargon) for its salesforce. In almost no case is this quantity known.
On first glance, this does not look like a supervised machine learning problem. But what if a researcher changed the question to: Can I predict a “realistic wallet?” That is, can I predict the maximum amount a given customer could spend with my company if they wanted to use it for all needs for which we have a solution? Some customers must have a deep brand relationship already, but the company cannot tell which ones they are just by looking at per-customer sales data.
As it happens, knowing this information isn’t actually necessary to have a well-defined supervised learning task. Rather than predicting some conditional expected value (a classical regression task), we really just need to estimate a high-condition revenue percentile. To do this, all that’s required is changing the loss function from sum of squared error to quantile loss (sum of weighted absolute error). Or in the case of a regression tree – rather than predicting the average in the leaf, pick a near maximum of the revenue numbers of the customers in each leaf.
4. When you need to decide which “wrong” problem is the right one to solve
Sometimes researchers know what problem we’re trying to solve, but we don’t have enough of the ideal type of

data to solve it. In these cases, intuition can help us find a suitable proxy that has a lot more data, either in terms of examples or just labels.
Let’s say a researcher wanted to model economic development in regions where reliable economic data was scarce. Perhaps measuring an area’s luminosity at night would be a good proxy for economic activity, as the following image suggests. It shows the seeming “absence” of impoverished North Korea, situated between two more prosperous seas of light: China and South Korea.
While measuring an area’s luminosity at night is a potentially good proxy for economic activity, one study from Stanford aimed to provide insight into other structural indicators. So, night luminosity was used as the target variable on images taken during the day. It revealed a number of interesting indicators of increasing relative affluence, like the existence of swimming pools or the type of material used for roofing.
Transfer learning
A more sophisticated concept of “transfer learning”—storing knowledge gained from one problem and applying it to another problem—is receiving a good amount of attention lately, particularly in the field of deep learning.
Consider the hypothetical case of building a sentiment model for a very influential figure in finance, the Federal Reserve Chair (as of this writing, Jerome Powell), based on publicly available photographs of his face.
Facial sentiment models require a very large number of training instances, far more than the number available of photos of Mr. Powell’s face. There is, however, a consistent physiological mechanism for reflecting emotions on virtually all human faces, not just Mr. Powell’s.

So, rather than building a model from scratch, an intuitive first iteration might be built on a large corpus of happy and less-happy human faces drawn from publicly available data sources, such as ImageNet.
Of course, the general population of Gen Z selfies is not exactly a perfect proxy for Mr. Powell’s more reserved appearance. So, the next step might be to make a more representative sample (probably male, formally dressed, similar age) to train the initial model.
This is an example of explicitly starting with the wrong data, and trying to transfer learnings from it to the real problem at hand. The actual “transfer” would happen in a second round of training, as the model is fine-tuned using the much smaller but more relevant sample of hand-labeled images of Jerome Powell himself.
Both of these approaches illustrate ways in which intuitive, human guidance is essential for the valid application of machine learning techniques to difficult problems.
5. When the “right” model is predicting the wrong things
Predictive models have absolutely no common sense when it comes to questioning what researchers are asking them to predict. A model will optimize whatever is provided in the training data to be as “good” (per a researcher’s definition) as possible, even if its output is patently absurd.
It therefore falls to the creator of the model to ensure that the designated task is the right one. Specifying this can be more difficult than one may think, and a post-mortem analysis of the model might reveal surprises.
The chart below, for example, shows which category of mobile app is most likely to entice a user to click on an ad, according to a machine learning model. Interestingly, it did not matter what the ad was for, or what the user was interested in. The thing that best predicted a high probability of a click was the context in which the ad would be shown.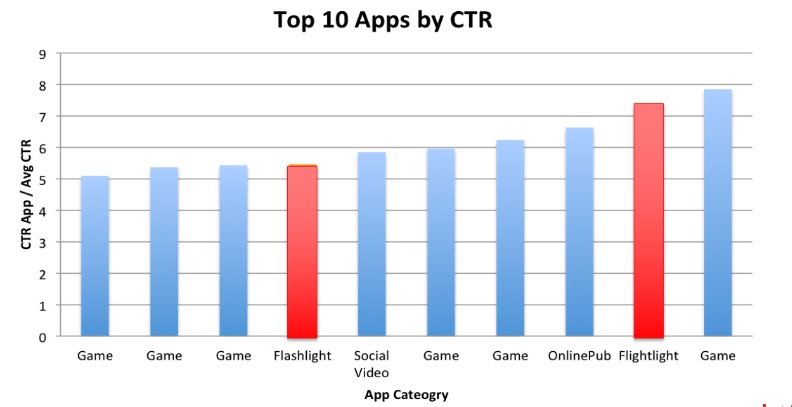
Ex-post, the fact that flashlight apps stood out may not be surprising at all. Studies (and personal experience) show that a large number of ad clicks are accidental. Indeed, when using a flashlight app, the chance that people are fumbling in the dark and accidentally clicking on the ad is very high—and also very predictable, if you’re a human!
Not surprisingly, those clicks have no correlation with purchase intent whatsoever. In fact, models created to predict clicks (and which do predict clicks very well) are frequently no better than random at predicting subsequent purchases.
Models are “lazy” and like to focus on what is easy to predict.
Putting aside the question of how useful click models even are, there is a very important lesson to be learned from this example: Models are “lazy” and like to focus on what is easy to predict.
Once again, human common sense and intuition are absolutely essential.
6. When a model’s predictions might be biased
A very important implication of the tendency of models to favor “easy” predictions is the potential to introduce biases on both ends of the prediction range. In the case of advertising, this might mean that most ads target heavily accidental circumstances (like flashlight app users).
Consider, too, a model whose purpose is to predict who might show up at an airport and potentially buy something. Absent a healthy dose of intuition on the part of a researcher, the highest scoring individuals are likely not to be spendthrift travelers, but rather pilots, stewardesses, and a large population of airport workers.
Models’ tendency to make “easy” predictions in this way opens the door to bias. The problem is, today we see such models being used to recommend job candidates, assign risk scores for recidivism, and predict criminal activity for policing purposes. While the overall evidence is that in comparison to humans, machine learning models tend to do better in terms of fairness, continued vigilance is crucial to ensure unbiased training data.
Data scientists can try to de-bias their data… But doing so does not absolve one of the responsibility to ensure a model isn’t still being biased in its predictions.
Even so, such practices may not prevent the biases that models can inadvertently create based on what is easiest to predict. Data scientists can try to de-bias their data, and they should. But doing so does not absolve one of the responsibility to ensure a model isn’t still being biased in its predictions. It’s never a good idea to delegate moral responsibility to technology. Here again, human judgment really matters.
7. When your model is too good to be true
One of the primary applications of human intuition is to provide a sense of how well a model can possibly perform. In other words, the researcher must be skeptical in a way a computer cannot be. If a model’s performance is much better than expected, maybe it is worth taking a closer look!
Sometimes knowing when to be skeptical is easy: Predicting asset returns is hard and being even just a few percent better than random can lead to an incredibly successful investment strategy. But being much better than that should always trigger an in depth analysis to make sure no accidental hindsight bias has snuck into the dataset. Figuring that out may require a good bit of detective work, intuition and judgment.
In other cases something else could be at work. For example, data scientists at an ad-tech firm once noticed that over a short period, several models predicting all kinds of online behavior (signing up for trials, downloading white papers, visiting brands’ homepages, etc.) showed a notable increase in their median predictive performance.
What caused this step-change? The researchers discovered, not a great new source of signal, but rather the digital footprint of a new generation of ad-fraud algorithms. These newer bots didn’t simply generate fake clicks; they were actually designed to generate much higher revenue in online ad auctions by taking actions that brands want people to take, like signing up for trials.
In this case, the bots were notably more predictable than real people—a dead giveaway to a data scientist using their intuition.
8. When you might be missing something (probably in your data)
A more subtle category of models that are “too good to be true” stems from information somehow being created by your data collection process and then finding its way into your training data.
Say you’re an individual who wants to invest through a peer-to-peer lending company. Loan application data may be available, along with information about borrowers, and so on. You’d probably also have information on whether previous loans were paid back in full or defaulted.
Using only 12-month loans for which the outcome is clear, and leaving aside those that are still outstanding (neither defaulted nor paid off yet), you are likely to learn a model that is “too good” at identifying loans with an artificially high default probability: basically every loan issued in the last 11 months.
Why? Our common sense tells us that outstanding recent loans with a duration of 12 months or longer cannot have been paid back. In other words, this dataset contains no examples of recent “good,” paid-off loans, but it would have some examples of defaults, thus skewing the data. The default label in this case becomes available much faster than the “non-default” label. So, the correct approach here would be to exclude any loans in the dataset that are younger than their nominal duration.
9. When it’s unclear whether—or how much—your model can generalize
Generalization typically refers to new instances where predictions will be used. Under good practice, a model would have already evaluated on data that had not been used for estimation. That evaluation is, however, only the first step, and it still would only have been performed on data that was available at the time of the model’s creation.
A common concern is that the model’s performance might deteriorate when it sees new data that’s somehow different—an obvious violation of IID that’s sometimes known as “concept drift.”
Consider the following case, drawn from a real-world example: A medical equipment manufacturer is hoping to aid breast cancer detection by creating a model that can predict the probability of cancer based on labeled, gray-scale mammography images from four different facilities.
The model appears to perform well on a holdout set. But researchers discover, to their concern, that (presumably random) patient identifier numbers are very predictive when added to the model.
One typically wouldn’t expect patient IDs to contain information relevant to the model (i.e., IDs wouldn’t normally indicate who has cancer and who doesn’t), but in this case they do—a fact that reveals a hidden story about the data with deep implications regarding generalization.
The data was collected from four different pieces of mammography equipment, each at a different facility. Each of these facilities had a different numerical range of patient ID numbers. The data shows these blocks of IDs clearly, but it also shows that the cancer incident rates were vastly different among them.
Why might this be so? How could patient IDs “predict” rates of cancer incidence? The answer is that one block was from a screening center, another from a treatment facility, and so on. Cancer rates would naturally be much higher at the latter than at the former.
Is this strange outcome a problem? If the model were used in only one of those four facilities to predict probabilities of cancer, it would probably be okay. But could the model be used in any facility with this type of equipment? Only a much deeper look into the data reveals that the answer is “probably not.”
The reason is that the images themselves carry implicit information about the locations they came from—possibly stemming from the calibration of the specific mammography machines in those locations, and small differences in the resulting average gray scales each produces.
In other words, this information “absorbs” the different cancer incidence rates. A location whose mammography equipment has a gray scale similar to that at location 1 (with a cancer incidence of nearly 36%), will always create, on average, higher probabilities than one similar to location 4, where cancer incidence is virtually zero.
Despite these distortions, the model can probably reliably rank patients: a higher score still indicates a higher chance of cancer. But is that good enough to release the model into the wild?
This case demonstrates how difficult making such a judgment can be—and why human intuition and experience is so critical to using ML models competently. Ultimately, only somebody with intimate knowledge of both the particularities of the training data and an understanding of the use-case can make the call.
Summing up
Working with advanced machine learning models has underscored a vital lesson: their effectiveness relies not just on the algorithms but also heavily on human intuition. The creator, intimately familiar with the model and its data, plays an irreplaceable role. From tackling challenges and selecting the appropriate data to ensuring ethical use, human judgment is—and will remain—crucial. As machine learning progresses, the blend of human insight and technology will continue to be fundamental for success.


