With hundreds of developers working on thousands of interconnected components, Two Sigma needs a software versioning and release system that’s both scalable and stable. In Part 1 of this series, Head of Software Development Life Cycle, Nico Kicillof, explains the rationale behind the process we call “head-to-head development.” Part 2 examines some of the challenges that organizations implementing a similar approach may face.
The Problem
Groups of developers working on single products can use most development practices with little issue. They can pick up versioned dependencies as needed, and can perform offline integrations to test and incorporate new features.
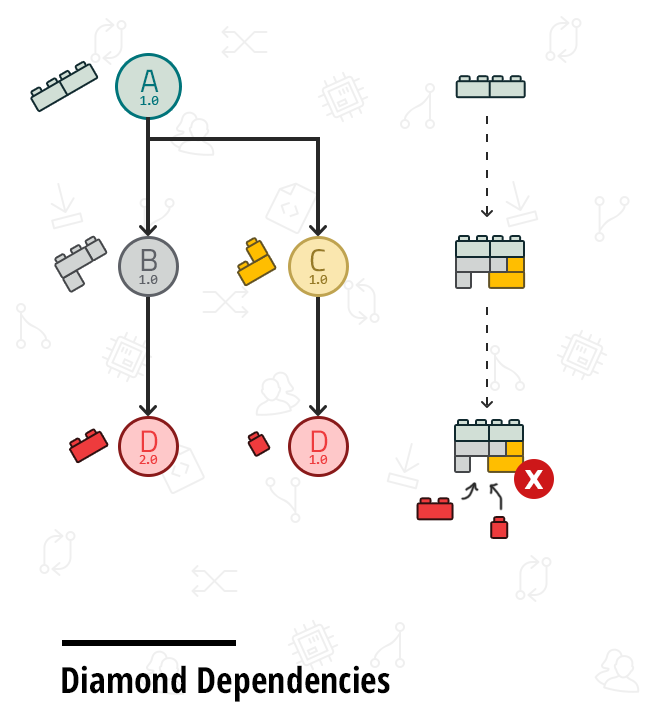
In a large organization with multiple products, though, these practices begin to break down. Typically, an organization wants its projects to evolve in lockstep, with a high degree of sharing and reuse. If a team acts in isolation, changing a feature or fixing a bug in a base library can lead to a tsunami of integration challenges. As consuming groups insulate themselves from changes, versions proliferate, diamond-dependency conflicts arise, and the entire organization begins to suffer from burdensome technical debt.
Our Solution: Head-to-Head
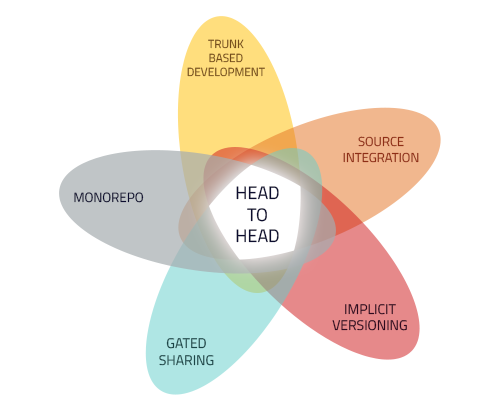
At Two Sigma, we’ve addressed the dependency and reuse problem by adhering to a “head-to-head” development process that combines several industry practices:
- Trunk-Based Development: Developers make most changes to each component within a single (trunk) branch. Production software ships from release branches. Developers are expected to merge changes made in feature development branches back into the trunk frequently.1,2
- Monorepo: All components share a single monolithic code repository and branch together, at the same time. A monorepo doesn’t imply a single, monolithic product or service. Rather, monorepo just means that the organization maintains all its code together, in a single repository.3,4,5,6
- Source Integration: All components and their dependencies can be built from source files in a single build event (this doesn’t mean they must be). Source integration systems can cache partial build and test results for reuse in subsequent events to achieve varying measures of incrementality.
- Gated Sharing: Before code can be shared with others through a central repository, it must pass a set of basic validations.7
- Implicit Versioning: There is no explicit specification of the version of a component a piece of code depends upon. Instead, source control revisions act as an implicit versioning mechanism.
Most organizations apply only a subset of these practices. For example, some companies do trunk-based development per component and consume dependencies as binary packages that are explicitly versioned. Others maintain a monolithic code tree and integrate sources, but only run validations such as builds and tests after integrating a change. In this case, they usually have processes in place to roll back or isolate changes that break builds or tests until the underlying causes of the breaks are fixed.
Unifying the practices above into a single process has allowed us to guarantee a certain level of software quality. We rely on workflows and tooling to ensure we maintain this quality over time.
Alternatives to Head-to-Head
Organizations and communities that don’t follow the head-to-head approach usually apply hybrid alternatives. These tend to employ some of the practices in head-to-head, but replace others with alternate methods for integrating software components. The following are alternates to each head-to-head practice:
- Trunk-Based Development: Source-control branches that are shared across a large organization can be organized according to different topologies. See Brendan Murphy, Jacek Czerwonka and Laurie William’s technical report8 for a possible taxonomy.
- Monorepo: The obvious alternative is for different teams to maintain their own independent repositories, either on a shared instance of a version-control system or on separate ones. Note that a monorepo is not a prerequisite for trunk-based development; an organization can maintain multiple repositories, with developers submitting their code to single branches in each.
- Source Integration: Organizations or communities that maintain more than one component and that don’t build them in a single build event generally rely on some form of binary integration. This basically boils down to building the components separately and picking up the build artifacts for dependencies from a well-known location to which they’re published (e.g., a package manager, shared file system, or source control repository). A continuous integration (CI) system can be used to automate the process of stitching components together.
- Gated Sharing: Validations can occur at multiple points in the development lifecycle; gated sharing is just a way to ensure that some of these validations “fail fast” (as close to the source of the change as possible), and that the central code repository remains healthy at all times. Organizations can prevent developers from submitting potentially offending code without performing validations at sharing time. For example, a group could launch basic tests or fully integrated builds of a system immediately after each change appeared in the central repository (or on a periodic schedule). In cases where validations fail, the organization can force an automatic rollback or use mechanisms such as email to provide out-of-bound feedback to parties responsible for remediation.
- Implicit Versioning: The purpose of implicit versioning is to integrate each component with the “latest” version of its dependencies at the time it’s modified. The opposite approach adopted by many dependency-management systems is to allow component owners to tag their components with version identifiers (usually following semantic versioning9) that can then be pinned by dependents. Those dependents can then choose to ignore future changes to the component and continue to evolve based on the pinned version.
Making the Choice: Head-to-Head vs. the Alternatives
Independent organizations with relatively few projects can achieve success with decoupled approaches, such as voluntary pickup of dependency releases or offline integration. As an organization grows to comprise multiple teams and projects, these schemes may begin to fall short. In particular, large organizations realize substantial benefits when projects evolve in lockstep with a high degree of sharing and reuse. Approaches that are good for loosely coupled communities often result in steep integration costs, version profusion issues, diamond-dependency conflicts and other forms of technical debt. In these settings, the introduction of a large-scale breaking change or critical bug fix in a base library can be a paralyzing event.
The goal of head-to-head development is to maintain a frontier consisting of a single master version of each of our components at all times. We call this version head because it is found at the tip of a branch in the central repository. The approach is known as “head-to-head” because it integrates the version at head of each component with the version at the head of all other components that it depends upon, and that depends upon it. Components at the frontier are considered safe to develop against because they have jointly been validated against a set of basic health criteria.
While the single master version of each component lives in the default (single-trunk) branch, validations are also performed for changes that target most branches in the central repository. This means that head-to-head integration is also guaranteed per branch. The only exception to this rule are branches designated as agile, meaning they don’t require all gates to be cleared in order to push code to them. The system polices the boundaries between agile and non-agile branches to ensure that all changes are validated before they propagate to a gated branch.
At a high level, our validations ensure (1) that changes have undergone a code review, (2) that we can build the whole source tree, and (3) that the resulting build artifacts pass all tests included in sharing gates. We call these pre-push tests because we execute them before code is pushed to the central repository (and thereby made visible to others).
Two Sigma’s system is designed to offer global incrementality, which means that the results of all builds and test events are stored in a central location for reuse as needed. As a result of this design choice, most validations only require builds and tests to run for changed code and its dependents. With this delta-driven process in mind, we’ve articulated our specific validation requirements as follows:
- All components whose code is modified by a candidate push must successfully build against all dependencies.
- All pre-push tests associated with modified components must pass.
- Downstream dependencies of a changed component must successfully build against the changed component.
- Pre-push tests associated with these dependents must also pass.
- Changes must be reviewed and approved.
Pre-push tests prevent code changes to components from breaking functionality in those components or in any code that’s located at the head of the branch being pushed to and that depends upon those components. Although pre-push tests are generally run using a unit test framework, they are by no means limited to unit tests. Proper unit tests focus on a small piece of a system (a unit, e.g. one method) and check it in isolation. Head-to-head pre-push tests are more akin to traditional integration tests, in that they validate a set of components for interoperability.
One difference with general approaches to integration testing is in the way versions of components to be integrated are selected. Due to their goal and the practice of implicit versioning, head-to-head pre-push tests are limited to the version of each component that can be found at the tip of the branch at the time of the push. Also like unit tests, head-to-head pre-push tests must be deterministic and they must run quickly (as thousands of tests are often required to pass at the time a developer attempts a push). Pre-push tests can only depend on code under source control; any dependency on external systems or services must be mocked. Integration scenarios validated by pre-push tests are generally limited to libraries or services that can be quickly stood up and torn down.
Benefits of Head-to-Head
Two key tenets of head-to-head development are technical debt curbing and blame attribution. In particular, head-to-head averts the situation where a component is modified in a way that breaks dependents, but is still allowed to evolve to a point where the offending change is difficult to find and fix.
Let’s consider how such a scenario usually plays out without each of the practices in head-to-head. If two components in a dependency relationship are allowed to accumulate changes in separate branches (no trunk-based development) or repositories (no monorepo), discovery of the break is postponed to the time the components are merged. At that point, an investigation must be launched to determine which of the many changes coming from either side is to blame for the break.
Using binary (not source) integration effectively turns the merged components into black boxes at merge time. Depending on integration frequency and the nature of the break, an issue might not surface until the dependent is built or until the components are tested in integration. When this happens, the source code for the upstream component or the justification for the changes it included might not be readily available to the individuals responsible for the integration.
Without blocking validations (no gated sharing), nothing prevents the upstream component’s code causing the break to be published. If there is a validation in place to detect build or test breaks in the downstream component, it will likely execute at one of three possible times: periodically on a fixed schedule (e.g., nightly), when changes are directly made to the downstream, or as a post-sharing validation triggered by committing the upstream change to central source control. The timeframe for this validation can determine the cost of fixing the problem:
- If a continuous integration system runs validations periodically, it might pick up multiple changes to the upstream or changes to multiple dependencies. This makes the task of identifying the offending code far from trivial.
- The problem worsens if the validation is postponed until the dependent’s code changes since, for a stable project, this could happen weeks or months after the upstream release.
- A system running validations (builds, tests, etc.) immediately after each contribution offers the closest blame-attribution benefits to gated sharing. Although this approach succeeds at detecting the break and pinpointing its origin sooner, changes have already been available to the organization by that time, which risks spreading the damage.
In all these alternatives to gated sharing, detecting a break usually launches a process requiring human intervention. Typically, the offending developer (or a group of potential offenders) receives a notification with a call to action. The need for human intervention increases the cost of fixing the issue. It can also result in accumulation of a huge technical debt, depending on how strict the organization’s code remediation policies are.
Of all the departures from head-to-head, though, none is more detrimental to the tenets of technical debt curbing and blame attribution than allowing developers to choose specific versions of each dependency (no implicit dependencies). This flexibility makes it almost impossible to predict how long it will take for owners of a downstream component to pick up a version of their dependencies that contains a breaking change. Not only does the lack of implicit dependencies introduce the late detection problem described above, it also requires owners of upstream components to maintain multiple versions (and potentially create patches for all of them if hot fixes are needed). This is a particularly expensive form of technical debt, considering that a patch, even if back-ported to one or more previous versions, doesn’t automatically propagate to consumers.
Beyond late-detection and expensive maintenance, the explicit decision to have a downstream component depend on hand-selected versions of their dependencies shifts the responsibility for ensuring interoperability from the provider to the consumer. The person most familiar with the breaking change and its intent is not the one adapting existing code to it. In a corporate setting where an entire codebase is owned by a single entity, it’s neither necessary nor efficient to have maintainers of dependent projects investigate and drive fixes to problems caused by changes in an upstream dependency. It misses the opportunity to reduce context switching and leverage the knowledge where and when it’s available. Notice that implicit dependencies are also an effective way to avoid certain diamond-dependency issues, consisting of a component transitively depending on two different versions of another component that cannot coexist in a build or run environment.
In Part 2…
As we’ve seen, Part 1 of Two Sigma’s Head-to-Head Development series addresses the key merits of this development model relative to common alternatives. Of course, head-to-head raises its own share of challenges, too.
Part 2 identifies some of the most critical such challenges, including those relating to scalability, incrementality, stability, and culture. It will also offer ideas on how to address them through automation and other means.