
The International Conference on Learning Representations is one of the premier international conferences on machine learning, with a special focus on deep learning (also known as representation learning). As we have in past years, Two Sigma sponsored the ICLR 2021, which took place virtually in May.
ICLR and similar conferences, such as ICML and NeurIPS, showcase the cutting edge in machine learning and related fields, such as statistics, data science, and robotics. Bringing together academics, industry practitioners, entrepreneurs, and more, these conferences provide opportunities not only for Two Sigma to learn about recent advances but to contribute to the broader machine learning community, as well.
Several Two Sigma researchers attended ICLR 2021. In this article, three of them, Austin Shin, Nick Petosa, and Raoul Khouri, share some of the papers and presentations they found most interesting, grouped by theme. In particular, they highlight papers that have broad practical applicability in many different domains.
Learning without forgetting
Ideally, models should be able to learn from new data without forgetting old knowledge. Neural networks have been observed to suffer from catastrophically forgetting old tasks when updated with new ones.
Gradient Projection Memory for Continual Learning introduces an orthogonal gradient descent method that fine-tunes for a new task while mitigating performance degradation of the previous task. This is done by maintaining a memory of important gradient directions of the initial task and then orthogonalizing against it for gradient updates for the new task.
Gradient Vaccine: Investigating and Improving Multi-task Optimization in Massively Multilingual Models proposes a modification to the gradient projection methodology where, instead of orthogonalizing gradients, the authors modify the gradients to a target cosine similarity. They show results for multi-language translation where performance improves by setting the gradient cosine similarities to similarities between different languages.

Few-shot learning
Few-shot learning is a training regime in which researchers only have access to a few (e.g. less than 5) samples from which to build a model. Accommodating such limited data is an important problem in fields where labeled training examples are difficult or expensive to come by, such as diagnostic medical imaging. Few-shot approaches work by fine-tuning an existing model from a plentiful source domain with data from the sparse target domain. The following papers introduce novel methods for improving this fine-tuning method.
Self-training for Few-shot Transfer Across Extreme Task Differences presents one such method. In the case where there are few labeled samples but many unlabeled samples for a domain, the authors use clusters of labels assigned by the original untuned model on the unlabeled samples as new additional labels. This improves fine-tuning performance in situations where the source and target domains are very different.
Free Lunch for Few-shot Learning: Distribution Calibration addresses another challenge with few-shot learning. Fine-tuning a pre-trained model with a small number of samples from a novel class can lead to severe overfitting. This paper’s approach finds examples from the most similar existing classes of the pre-trained model and uses them as additional training samples for the novel classes.
Robust optimization
Neural nets are susceptible to learning spurious relationships in data. This can lead to models that perform poorly on unseen data and that are susceptible to adversarial attacks. Several papers presented at ICLR 2021 address these robustness challenges.
Sharpness-aware Minimization for Efficiently Improving Generalization (SAM) introduces a loss term that encourages convergence on smooth, flat regions rather than sharp minima. This is done by optimizing for a neighborhood of parameters that have uniformly low loss.
A particularly interesting aspect of the authors’ approach is that practitioners only need to take a small gradient step in reverse, then recalculate a gradient from there (the worst neighbor) and take a large step out of the worst nearby location. It is, in effect, like stepping backwards to go forward. The approach is relatively simple but effective. Additionally, it improves robustness to label noise, which tends to occur regularly in real-world data.

Systematic Generalisation with Group Invariant Predictions attempts to improve robustness to distributional shift by encouraging dependence on complex but semantically meaningful features over simpler, less meaningful features that just happen to correlate well with the label.

For example, this technique can be used to train a net to recognize a written number not by its color but by its shape.
This paper’s technique is broadly applicable across domains—particularly in data-starved scenarios, where it’s harder to learn robust feature representations from a small number of samples.
Consider a healthcare-related example that one of us encountered in a previous role: When training a classifier on medical images, the model learned to detect the background colors of the offices in which images were captured—rather than the semantic content of the image itself—to make decisions. This occurred because that feature was easier for it to learn than the actual subject of the images, and it just happened to have a high correlation with the target. Data frequently has this type of issue, and the authors’ approach would help address them.

———
Mixup is a popular data augmentation technique, introduced at ICLR 2018, in which new training data is generated by taking linear combinations of existing training data. How Does Mixup Help With Robustness and Generalization? provides theoretical analyses demonstrating how applying Mixup both implicitly minimizes an adversarial loss and implicitly applies data-adaptive regularization.
Post-deployment robustness
Deep neural networks achieve high accuracy when training and test sets are sampled from the same distribution. In practice, however, production can require model inference on samples from different distributions due to research or deployment constraints. These papers propose methodologies for improving robustness by making online model updates.
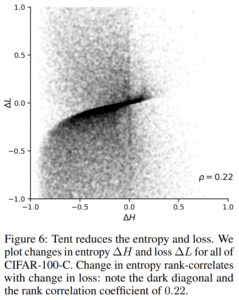
Tent: Fully Test-Time Adaptation by Entropy Minimization proposes an online modulation of features by estimating normalization statistics and optimizing transformation parameters in the goal of minimizing entropy in deployment predictions. The authors show that when entropy is reduced with this methodology, loss also decreases. This methodology achieves state-of-the-art performance for the CIFAR-100-C and CIFAR-10-C corruption benchmarks.
Self-Supervised Policy Adaptation During Deployment (PAD) attempts to increase reinforcement learning policy robustness when deployed to a new environment by continuously learning after deployment without using any rewards. The method the authors employ is to add an additional target that is the angle at which observation frames have been rotated. The authors show that while using PAD RL agents are far more robust to changes in color, light, and texture in the observations.

Improving transformer runtime
Transformers1 are state-of-the-art models for several sequence modeling tasks, from language modeling to image classification to protein sequence modeling. One crucial element of transformers is an attention mechanism with runtime complexity quadratic in the sequence length. These papers aim to improve this runtime complexity, which can be prohibitive for long sequences. The fact that more than one paper at ICLR is addressing this specific issue demonstrates how important this problem is.
Random Feature Attention proposes replacing traditional attention with a random feature attention module that uses random features to approximate the softmax, instead of directly computing the softmax for each element in the sequence. This makes the runtime of attention linear in the sequence length without sacrificing accuracy and is especially beneficial for long sequences. For sequences longer than 1000, random feature attention provided more than a 5x speedup over softmax.
Rethinking Attention with Performers also aims to improve the runtime of attention from quadratic time to linear time using random features via a new approach the authors call Fast Attention Via Orthogonal Random Features (FAVOR). This approach can be used to speed up any kernalizable attention function—not just softmax—without losing accuracy. FAVOR produces strong performance across a variety of sequence modeling tasks, including pixel prediction, text modeling, and protein sequence modeling.
Convolutional neural networks/computer vision
State-of-the-art convolutional neural networks (CNNs) continue to improve on computer vision tasks. The following papers from ICLR 2021 broadly address learning and representation issues when training convolutional neural networks on image datasets.
In Mind the Pad —CNNs can Develop Blind Spots, the authors explore how zero-padding in convolutional filters can cause spatial biases that inhibit performance, especially when detecting small objects. This happens because sometimes padding is applied unevenly, leading to asymmetric kernel weights and blind spots. The authors show how to mitigate this effect by using mirror padding or circular padding. Zero-padding has long been a standard in CNN design, but this paper demonstrates that, even 10 years after the seminal deep learning work on AlexNet, the computer vision community’s understanding of how these models work continues to evolve in meaningful ways.

Conventional wisdom attributes CNN’s better inductive bias as the reason they are more sample efficient than fully-connected networks. The paper Why Are Convolutional Nets More Sample-Efficient than Fully-Connected Nets? shows that the number of samples required for generalization scales quadratically with input size for fully-connected networks. In contrast, for CNNs the scaling is independent of input size.
The Intrinsic Dimension of Images and Its Impact on Learning applies dimensionality estimation techniques to determine that standard image datasets like ImageNet have low dimensional structure. The paper also finds that models trained on datasets with low intrinsic dimension converge faster and generalize better to unseen data. The authors use GANs to validate this finding by explicitly controlling the dimension of generated images. It is reassuring to see that transformations that preserve dimensionality according to human perception, such as upscaling an image, also seem to be “understood” in the same way by deep learning models.
Learn more
For more deep learning conference highlights, plus additional insights from Two Sigma on deep learning more generally, be sure to check out https://www.twosigma.com/tag/deep-learning/


