
Imagine being asked to interpret and act on two numbers: 80.6, 50.0. Trying to do so without any additional context is apt to give you acute hypotension or send you fleeing to a frozen northern island. Hyperbole aside, data scientists frequently confront such challenges.
Often within systems, data is labeled only as the standard five software “primitive types,” leaving the consumer to infer what it represents. As these data are used to describe a myriad of more complex concepts, this leads to ambiguity and challenges in determining the meaning behind fields, columns, and entities.
The rise of data science, the inherent dirtiness of data, and the proliferation of vast numbers of data providers and data products all play a role in increasing the value proposition of semantic types. Semantic types are a way of encoding contextual information onto a data schema that informs the user as to the context of the data in a structured fashion. Integrating, validating, and joining this information remains a complex challenge. However, we think enhancing meta data with semantics is a concept worth a detailed look.
We would like to invite you on a journey with us as we explore the potential of semantic types for the Semantic Enrichment of Data (SED). We see semantic types, properly applied and standardized, as providing rich human-centric meaning to datasets. In this post, we:
- Tour potential use cases for semantic typing/mapping
- Explore opportunities for industry wide collaboration between data producers and consumers
- Share our view on how semantic types can improve an organization’s meta-data strategy
- Consider whether this technology can assist in streamlining the generation of type mappings for large language models (LLMs)
What are Semantic Types?
Semantic types are a way of encoding a common human-centric meaning of data. In the current state, this contextual data is stored separately, usually in unstructured forms such as documentation, data catalogs, or implicitly stored in the business logic of validations. The types represent real-world concepts that are an enhancement over the typical structures which define the way computers represent data.
An example is latitude and longitude. The two numbers are typically stored as two floats or a series of integers, and labeled with either lat, latitude, lon, longitude, or a multitude of other column names. With SED, the columnar types would be latitude and longitude, independent of what column name was assigned. The same could apply for heart rate variability data that is stored as a number of different integers.
While column names can help, often they are not defined consistently across datasets, resulting in potential for errors, confusion, friction, and integration challenges (e.g., lat vs latitude). Semantic types augment column names with machine-readable context. With SED, defining a semantic types and creating a semantic knowledge graph enables automated understanding of data. These structures unlock the ability to relate datasets using a machine which would normally only be relatable by human interpretation.
The Current Moment in Data
Data pipelines continue to increase in length and complexity for many domains, with alignment of many actors including vendors, engineers, and stakeholders in the business needed to maintain functionality, and quality. This complexity has become increasingly difficult to manage, communicate, and debug both at a human and technical level. Data science-driven organizations are currently at a moment where data mapping has become an increasingly important and painful step for organizations that ingest and synthesize a larger number of highly diverse datasets to execute their business.
We see semantic enrichment of data and knowledge management graphs as a way to help address these pain points, as well as mechanisms for crowdsourcing domain meta-knowledge and providing a principled and standardized way of communicating this data among organizations, people, and machines.
Tour of Use Cases
SEDing can help increase understanding and action within and between datasets across a diverse set of data challenges.
Richer Understanding of Primitive Types Increases Information Fidelity
Let’s look at an example: a data set of heart rate information, such as the HRV (heart rate variability, a measure of systematic-stress) provided by fitness watches, typically would be stored as a table of integers and floats. Context is needed to understand the exact meaning of these values, and poor naming exacerbates the challenge. For example:
Data types:

Table:

With semantic types:

From the assigned types we are immediately able to determine the nature of the data, its measurement, and how to interpret the numbers.
Joining and Linking
Let’s walk through a fusion use case. Imagine you are a runner who seeks to improve your marathon time through numerical analysis, and let’s say you have access to three datasets- one involving wind speeds from the weather station, one with elevation/geolocation data from a phone, and one with heart-rate variability from a smartwatch. You could extract many meaningful trends from the combination of these datasets, but in order to do so, the datasets have to be joined. However, each of these datasets have different schemas, whose time-based or location columns differ by type of measurement.

Joining data from “wind_speed” and “elevation” is difficult, because without human intervention, the relation between a suburb of a city and latitude/longitude is not directly joinable. Additionally, relating the time-based columns between all of the datasets is challenging because the ill-defined labels make it impossible to tell that the first is measured in hourly increments, the second is measured using the standard 12-hour clock, and the last is measured in mean time.
With semantic type, fuzzy joins become easier, because the locations and time-based columns can be correlated:
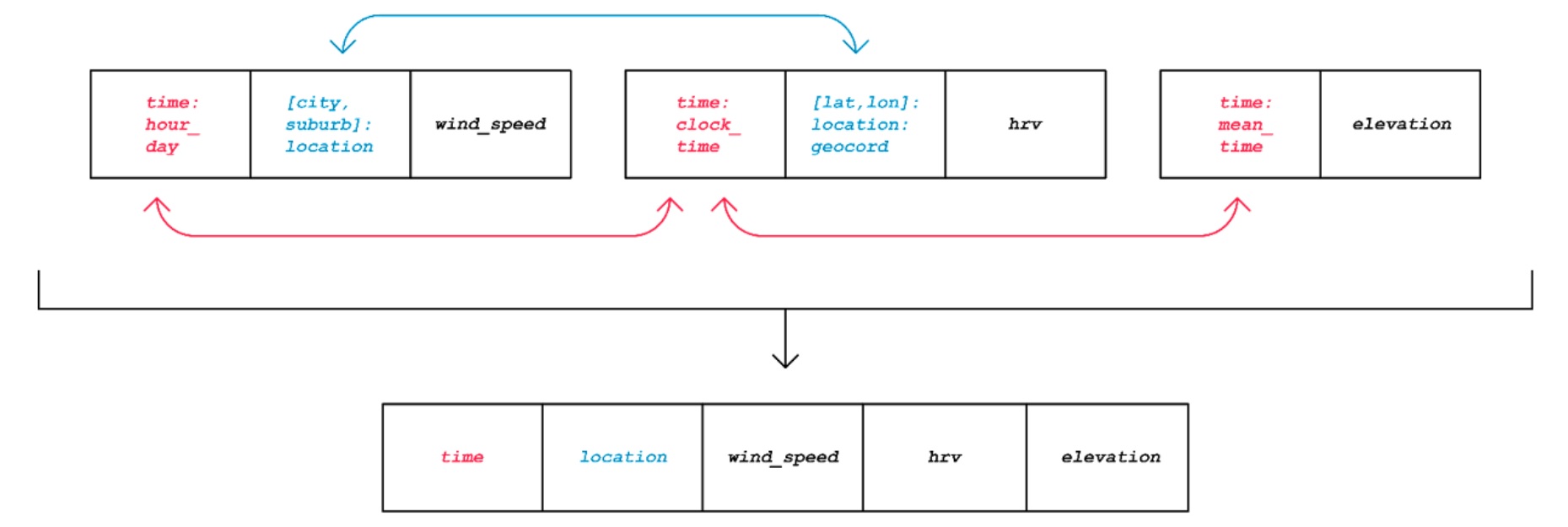
The resulting table allows us to answer questions like: “How do wind speeds close to the starting point of the run affect body stress levels?” or “Are outlier heart-rate variability detections correlated with the elevation/wind or the duration of my run?” Questions like these can only be answered with fully joined data, and semantic types help the stitching process.
Hierarchy, Graphs, and Typing
Hierarchical and graph-oriented typing systems enable the definition of relationships between types, and eventually datasets unlock the promise of SED to help build knowledge graphs, which can improve data discovery across vendors. The hierarchy can be important for advanced search and join capabilities. For example, knowing that a field is a location as a concept can enable a mapping between address and geocord. Since types encode meaning, they can be integrated into search experiences that provide links between datasets automatically without the need for human creation or reliance on traditional text-based search patterns.
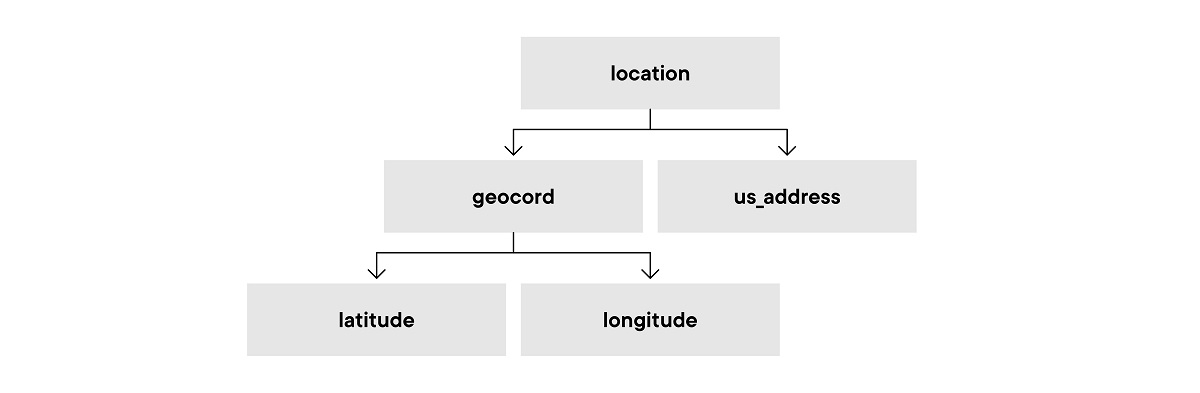
Systems could map heart rate variability to standards set by a number of healthcare organizations to enable labeling with other datasets:
hrv:HeartRateVariability a rdfs:Class ; rdfs:label "Heart Rate Variability" ; rdfs:subClassOf snomed:301113001 . # SNOMED CT code for "Finding of heart rate" or @prefix fhir: <http://hl7.org/fhir/> . hrv:HeartRateVariability rdfs:subClassOf fhir:Observation . hrv:measurementMethod rdfs:subPropertyOf fhir:Observation.method . hrv:unit rdfs:subPropertyOf fhir:Observation.valueQuantity.unit . hrv:value rdfs:subPropertyOf fhir:Observation.valueQuantity.value .
Context-Driven Automatic Validation
Once types are assigned, the ability to validate data becomes simpler. For example latitude and longitude must be within the ranges [-90.0,90.0] and [-180.0,180.0], respectively. A validator would be able to understand these ranges and provide explainable alerts if the data were out of specification. Additionally, smart validators could look out for default values, such as 0,0 or validate the precision of a measurement.
Context-driven validation, such as standard heart rate zones, could be used to provide instant analysis and visualization. The assignment of types would naturally allow the assignment of the zone values.
Implementation of SED Model
The benefit of semantic types is their ability to convey contextual information beyond standard naming conventions or data-types. We outlined several data engineering use-cases that take immediate advantage of this contextual information, but these rely upon a semantic type data model that currently doesn’t exist at a detailed level for many domains. Developing a generalized semantic type data model is challenging because the model must balance between generalization and over-specificity.

The model should capture the necessary diversity of semantic types required by users, while ensuring that the types convey unique and useful contextual information. We see a number of areas where agreement on requirements could help define a useful Semantic Typing Data Model:
- Standard domain – Semantic types inherently have to restrict the domain of a column in order to provide utility in mappings, validation, fusion, or discovery. For example, longitude should only range from [-90.0, 90.0], while latitude ranges from [-180.0, 180.0].
- Standard formatting – The structure of a semantic type together with its validations/domain should be standardized in a manner that users can consistently rely on. This is similar to efforts such as datetime standardization per ISO or stock-ticker standardization by CUSIP.
- Conversion patterns – Companies use a wide variety of formats/standards to represent entities, so it’s impractical to assume that the community will completely recompose their existing infrastructure to match a Semantic Typing Data Model. Therefore, our model must contain standard conversion patterns to map prior formats to those defined in the model.
- Organization – A generalizable Semantic Typing Data Model may spawn semantic types that have relationships to one another. Similar to knowledge graphs, we envision this model also consisting of hierarchical and/or actional relationships that can convey semantic relational information. For example, a “person” will “WEAR” a “smart-watch”, where “smart-watch” is a hierarchical subset of “measurement devices”.
- System Characteristics – For the technical implementation of the system itself, platform portability, extensibility, and composability are important features to enable integration and flexibility. We envision the Semantic Typing Data Model as an open-source library of semantic type definitions that clients can query/search over using a RMS-style query language like GraphQL or SparQL. The Semantic Typing Data Model will be stored as a knowledge graph, whose nodes contain properties such as units of measurement or utility function that perform mappings and whose edges contain hierarchical/actional relationships as defined in 4. In order to be broad enough to encompass the needs of various companies/industries, we suggest a democratic model where users can “push” or “edit” semantic type definitions, much like a GitHub-style pull request, and a governing body votes on accepting those changes into the centralized store.
Broader Applications
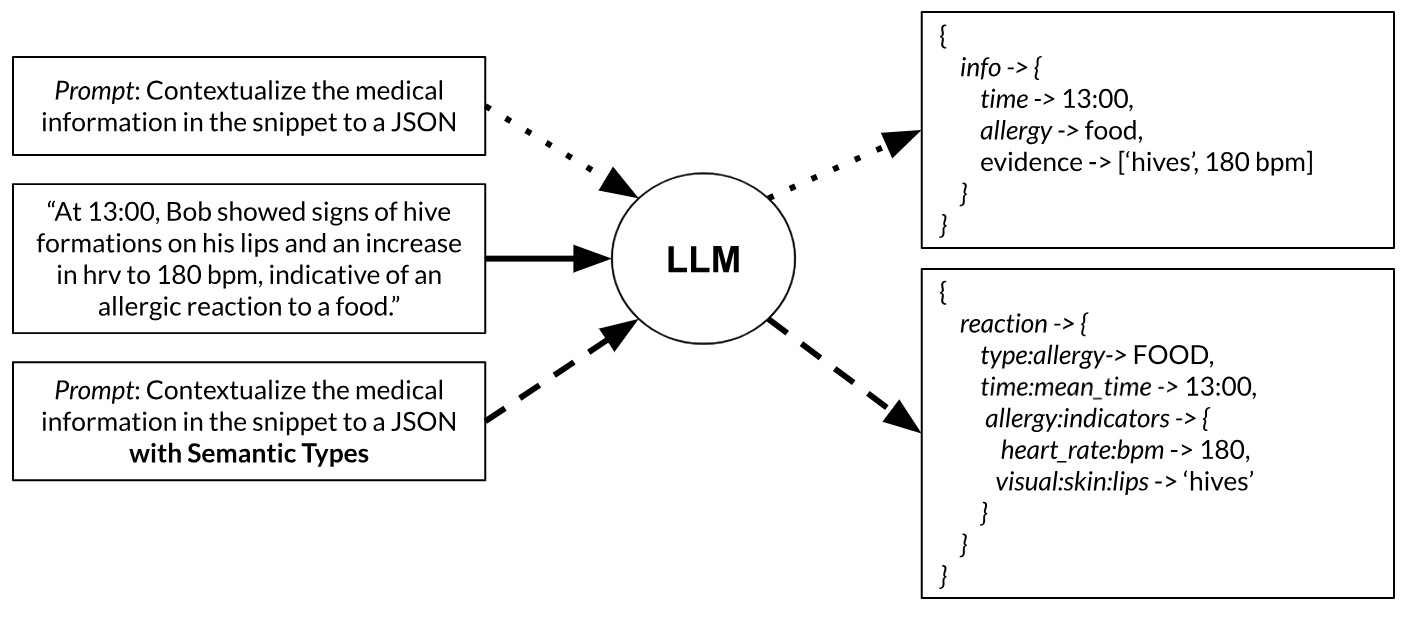
Large language models have gained wider adoption because they can extract domain specific information and procedures despite being trained on ambiguous text. Plug-and-playing LLMs into a business workflow is not necessarily simple, as a result of the complex human language outputs. Semantic types and LLMs fit closely together because semantic types can serve as the standardized language for enterprise interfacing with LLMs. Consider a process whereby a medical technician extracts metadata from documents into standardized JSON for downstream consumption. LLMs can aid in the process of extraction, but they need extra prompting to understand the format/nomenclature of the output. With semantic types, we hypothesize this may be resolved:
In order to automate the standardized mapping requirement of a Semantic Typing Data Model,
LLMs can be used to infer the semantic type corresponding to tabular data. DoDuo is an LLM trained to perform these mappings, so for instance, given the following column name and its values, “Place, New York, Chicago, Boston, …”, DoDuo predicts the corresponding semantic type: “city:location”. LLMs like DoDuo can help perform columnar data mappings at scale, which is crucial for companies that own large numbers of datatables.
These examples demonstrate the power of combining semantic types with LLMs. We believe that further understanding their relationship and applications will enable many business workflow optimizations.
Conclusion
The increasing diversity and scale of datasets has required companies to construct custom-fitting protocols to handle and name data. This often results in redundancy between data producers, data consumers, and their corresponding data engineering platforms, but we believe that semantic types can aid in solving this issue. Semantic types go beyond traditional data-types (like integers or strings), because they provide meaningful human-centric contextual information that conveys content. Context can aid in applications such as data fusion, discovery/search, validation, and automated conversion, but in order to achieve cross-company usability, there should exist a generalizable ontology for classifying semantic types.
Previous work has already begun identifying types such as credit card numbers, dates, latitude/longitude, and more, but there doesn’t yet exist an ontology that encapsulates the multitude of types more generally found in datasets. We suggest a need for a framework for how the data science community might open-source the creation of ontologies of semantic types, as well as the requirements to gain usability in the stated use-cases.
We see an opportunity for the needed collaboration across the community to develop a generalizable data model for semantic types, which would help pave the way for a more manageable data landscape. We hope this serves as an inspiration for others in the field to seek out like minded peers and begin to build a Semantic Enrichment of Data (SED)-driven future.


