
In 2020, right before the pandemic hit, we launched scout. This new, open source tool was designed to make it easier to discover the open datasets that you need for your work. It does so by recommending datasets that would be easy to join together, and those that have a similar theme. We have been working hard this year to broaden the reach of scout, allowing it to see into data portals beyond NYC.
We have also been exploring other ways that scout can make open data more accessible. During last month’s Open Data Week, we held a workshop to explore these potential new features with members of the open data community.
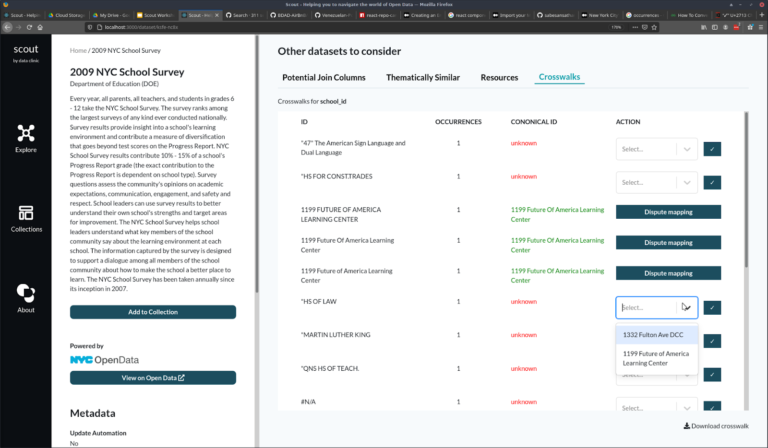
The first feature we wanted to explore was enabling scout to host community-curated crosswalks to standardize names, IDs, and categories across all of NYC’s open datasets. Joining datasets from the open data portal can often be tricky because IDs don’t match among or even within datasets. This can be due to different agencies using different standards, typos, or truncated names. For example, in datasets that contain a school_name column, there are 18,157 unique school names, but there are only 1,866 schools in NYC. This feature would allow users to submit mappings for each of these unique IDs to a canonical ID, creating clean versions of these datasets that are easier to work with.
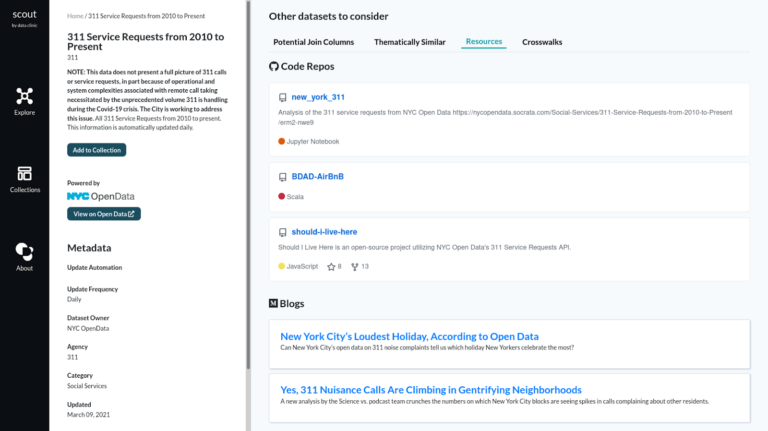
The second feature we were interested in highlighting the work that the community has done on a particular dataset. It can be hard to know where to start cleaning or exploring when encountering a dataset for the first time. Thankfully, you’re probably not the first person to use a given dataset. The internet is often full of GitHub repos, gists, cleaning scripts, blog posts, and tools that use the dataset you’re interested in. However, the challenge of finding these resources can lead to unnecessary duplicative work that reinvents the wheel.
We hope to solve for this challenge by adding a feature to scout that would allow resources relevant to a dataset to be shown alongside it. These resources could either be automatically identified or submitted by members of the community.
Thanks to the feedback from the community, we were able to validate that people really want and need these features. We also received many suggestions for the best ways to implement these ideas and considerations to account for.
We are excited to continue to expand scout’s usefulness as a community resource and will be working hard to implement new features over the next six months. Watch this space for updates, and reach out to us if you have any feature requests!
Finally, a huge thank you to everyone who attended the session, the Open Data Week team for making this all possible, and MODA and the open data coordinators for providing such an awesome data portal for us all to build off of!