
NeurIPS 2019 (also known as the Neural Information Processing Systems Conference), is one of the premier machine learning conferences—one of the “Big Three” that also includes ICML and ICLR. The latest event, which took place in Vancouver, featured more than 13,000 attendees, with 1,428 submissions having been accepted for presentation.
Two Sigma aims to remain at the forefront of machine learning research, and we highly value opportunities both to learn from our peers and to share ideas with them. As we’ve done since 2014, Two Sigma sponsored the NeurIPS 2019 conference, and several dozen of our researchers and engineers attended and/or presented. Below, we highlight a (by no means exhaustive) selection of particularly innovative, relevant, and interesting papers and presentations from the event.
Special thanks to Robert Chen, Rachel Malbin, Louis Shao, Peter Thill, Darren Vengroff, and Richard Wu for their contributions to this write-up.
Architectures and Optimization Methods for Big Data
NeurIPS 2019 covered many broad themes related to the challenges of training increasingly large models with large amounts of data. Even as researchers aim to improve sample efficiency, state-of-the-art models tend to have billions of parameters. Meanwhile, applications like self-driving cars, mobile applications, and IoT devices have memory and compute constraints. Thus, well-represented areas at NeurIPS included parallelizable optimization methods and models with fewer parameters, lower memory footprints, faster inference times, and easier distributability.
- Since it was introduced at NeurIPS 2017 (Vaswani et al.), the Transformer deep learning architecture has been used to achieve human-like performance on natural language tasks while also “transforming” other fields. Are Sixteen Heads Really Better than One? by Michel et al. experiments with, at inference time, removing heads from the multi-head self-attention of pre-trained Transformer models. The authors found that taking away 15 of 16 heads decayed performance less than expected. There was more dropoff in later layers and in encoder-decoder layers rather than encoder-encoder and decoder-decoder locations, which makes sense intuitively. Many of their experiments had a bit of the feel of the “lottery ticket hypothesis” line of work from ICLR 2019.
- Researchers also further studied and extended the lottery ticket hypothesis. Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask, by Zhou et al. investigated the heuristics behind the original lottery ticket paper’s pruning method. This Uber AI team found that the sign of the initial weights was what actually mattered in the initialization of the winning tickets, and that the pruning masks could be learned by optimization, resulting in supermasks that can enable untrained networks to score as well on testing accuracy as fully trained networks do.
- Weight-tied models have demonstrated marginal improvements over their non-weight-tied variants, such as the Universal Transformer from ICLR 2019. Deep Equilibrium Models by Bai et al. (DEQs) observed that empirically, inter-layer activations in state-of-the-art (SOTA) weight-tied models (such as the Universal Transformer) tended towards a fixed point. DEQ replaces N weight-tied layers with a single layer where the feedforward pass solves for the fixed point via root-finding instead of the canonical feedforward pass.
- X (Google X) demonstrated substituting tensor networks, inspired from quantum physics, into transformers to reduce the number of parameters and improve generative language model inference by a factor of two. It will be exciting to see the group’s tensor network publications in the year to come.
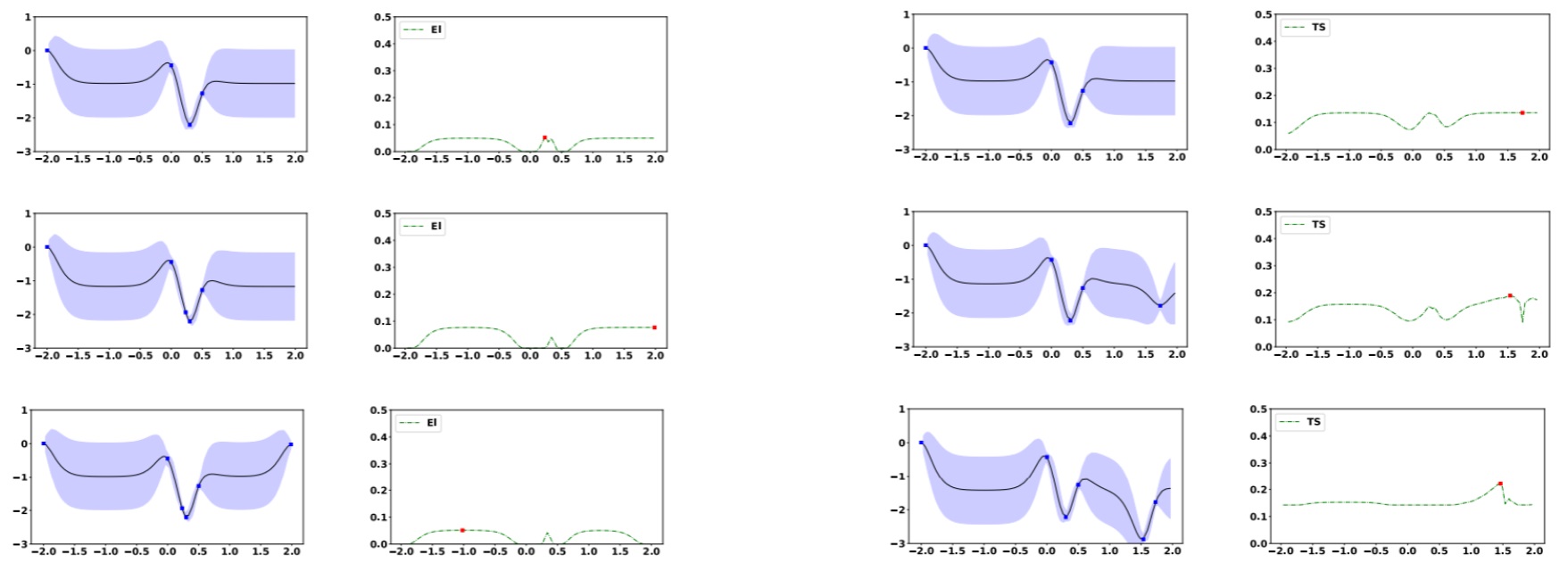
In Practical Two-Step Lookahead Bayesian Optimization by Wu et al., Jian Wu (Two Sigma) and Peter Frazier develop a computationally efficient approach to two-step Bayesian optimization. The method utilizes SGD with a new unbiased estimator of the gradient, and is parallelizable. The authors show further improvements using importance sampling and achieve promising empirical performance.
Benchmarks
As machine learning fields evolve and researchers develop newer and better algorithms for solving existing problems, it’s increasingly important to have widely-publicized, thoughtfully-designed standard baselines. Several research teams shared interesting approaches to this challenge at the 2019 NeurIPS conference.
- The natural-language processing (NLP) community has developed numerous language models whose parameters are trained using an unsupervised language corpus, before being “fine-tuned” to perform well on individual tasks. GLUE is a benchmark that provides a single-number metric for gauging the efficacy of natural-language understanding models, but increasingly, their performance (essentially, the difference between human and machine baselines) has become so good that a more challenging benchmark has become necessary. SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems by Wang et al. aims to fill this gap. It includes eight downstream language-understanding tasks, along with a software toolkit, and a public leaderboard.Example question (Causal reasoning task):
Premise: My body cast a shadow over the grass.
Question: What’s the CAUSE for this?
Alternative 1: The sun was rising.
Alternative 2: The grass was cut.
Correct Alternative: 1
Example question (Pronoun matching task):
Text: Mark told Pete many lies about himself, which Pete included in his book. He should have been more truthful.
Coreference (are the nouns referring to the same thing?): False
- Evaluating Protein Transfer Learning with TAPE by Rao et al. also consists of a benchmark of multiple tasks to evaluate self-supervised pretrained representations—in this case, for protein modeling. Example tasks include predicting the fluorescence intensity of a protein and predicting whether each pair of amino acids within a protein are nearby to each other.
Benchmarks are an area for machine learning researchers to keep an eye on. This is especially true in various areas of reinforcement learning (as the field matures), and for NLP, where rapid progress by papers like XLNet: Generalized Autoregressive Pretraining for Language Understanding by Yang et al. (presented at NeurIPS 2019) and other, newer models render older benchmarks less meaningful.
Training Objectives for Supervised Learning
NeurIPS 2019 featured numerous papers on developing creative loss functions via learning from data in a self-supervised manner or through inspiration from learning theory. Other entries encoded inductive biases into algorithms’ loss functions, a particularly helpful approach in low-data or high-noise settings, and of interest to practitioners who seek to incorporate domain-specific information into their machine learning approaches. Several of these innovations demonstrate promising empirical results.
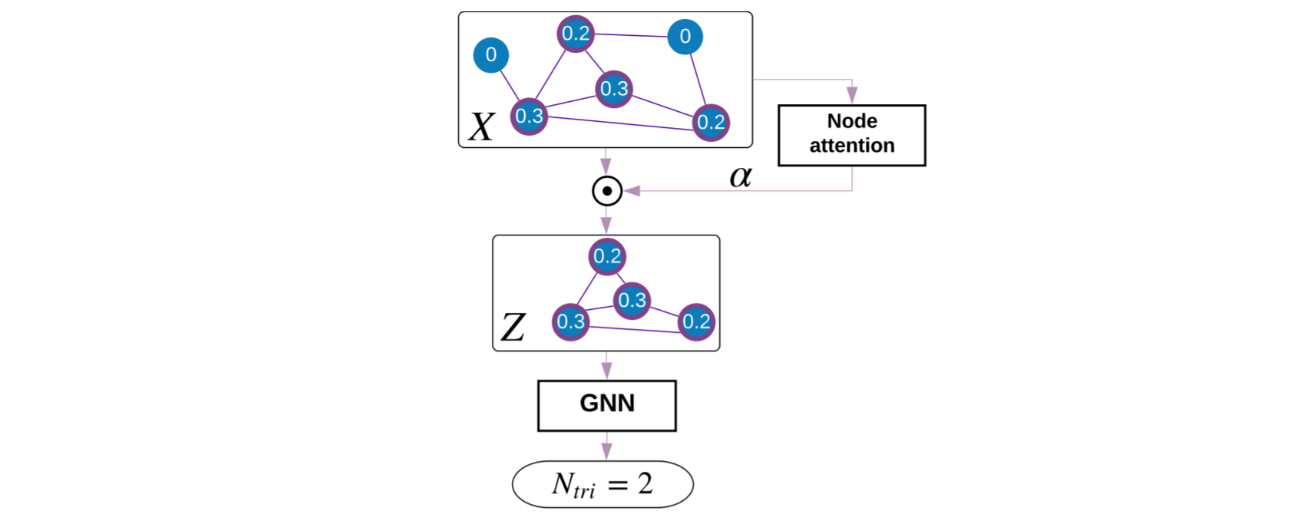
- When making predictions on graphs, quantifying the importance of nodes within the graph can be useful. Part of Understanding Attention and Generalization in Graph Neural Networks by Knyazev et al. shows that, in cases where we don’t have these importance values, we can still construct them from the data. Specifically, the authors train a graph neural network, then compute predictions with the model both as-is and with each node removed from the graph, and then use the differences as weights for training a new attention-based GNN. The loss function accounts for the main objective as well as how closely the model’s attention weights match the prior node importances.
- In Regularized Gradient Boosting by Cortes et al., the authors use a Rademacher complexity-based bound as a regularization term for training gradient-boosted trees. This is an interesting case of theory inspiring a change in the loss function for a practical algorithm. Combined with a principled approach to selecting more diverse weak learners and some optimization tricks, they are able to demonstrate improvements to XGBoost on a variety of datasets.
- In time series, the same pattern might occur at different times and be stretched differently, but still be the same meaningful feature. Dynamic Time Warping is a popular method for comparing time series to capture these properties. In DTWNet: A Dynamic Time Warping Network by Cai et al., the authors incorporate DTW between the input and different kernels to extract features, while maintaining a differentiability in the loss function for backpropagation.
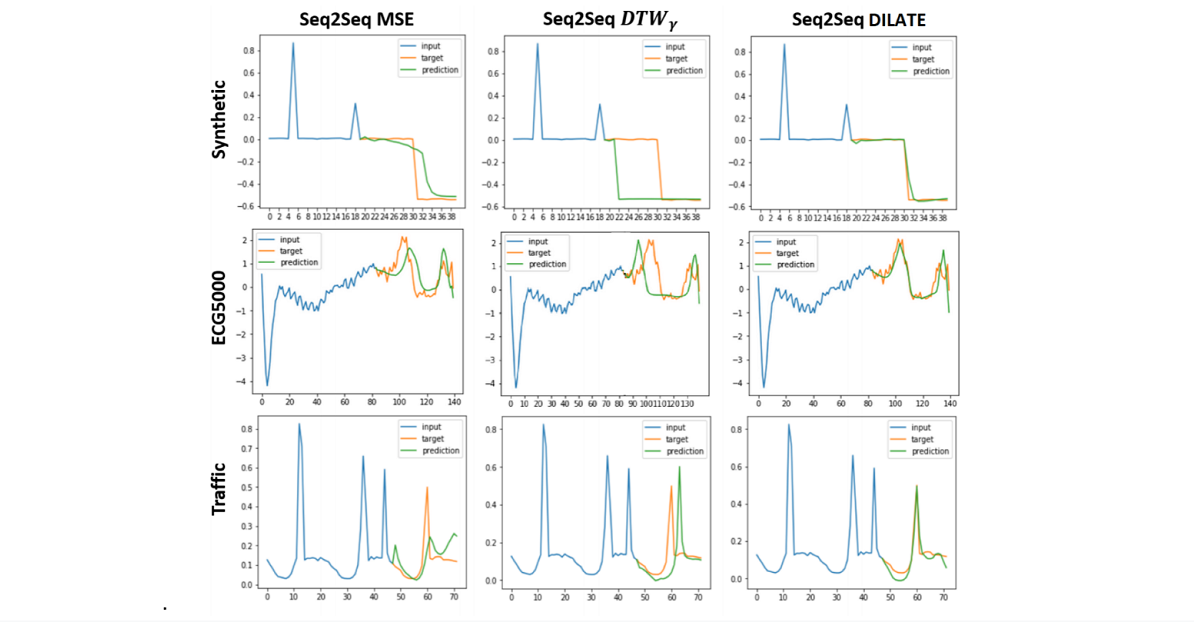
- Shape and Time Distortion Loss for Training Deep Time Series Forecasting Models by Le Guen et al. proposes DILATE, a (differentiable) objective that is a linear combination of a DTW-based term and a term to measure how far the optimal DTW warping path matrix is from diagonal. By accounting for both matching shape-wise and matching temporally, DILATE produces promising results in multi-step time series prediction.
Data-Efficient Reinforcement Learning
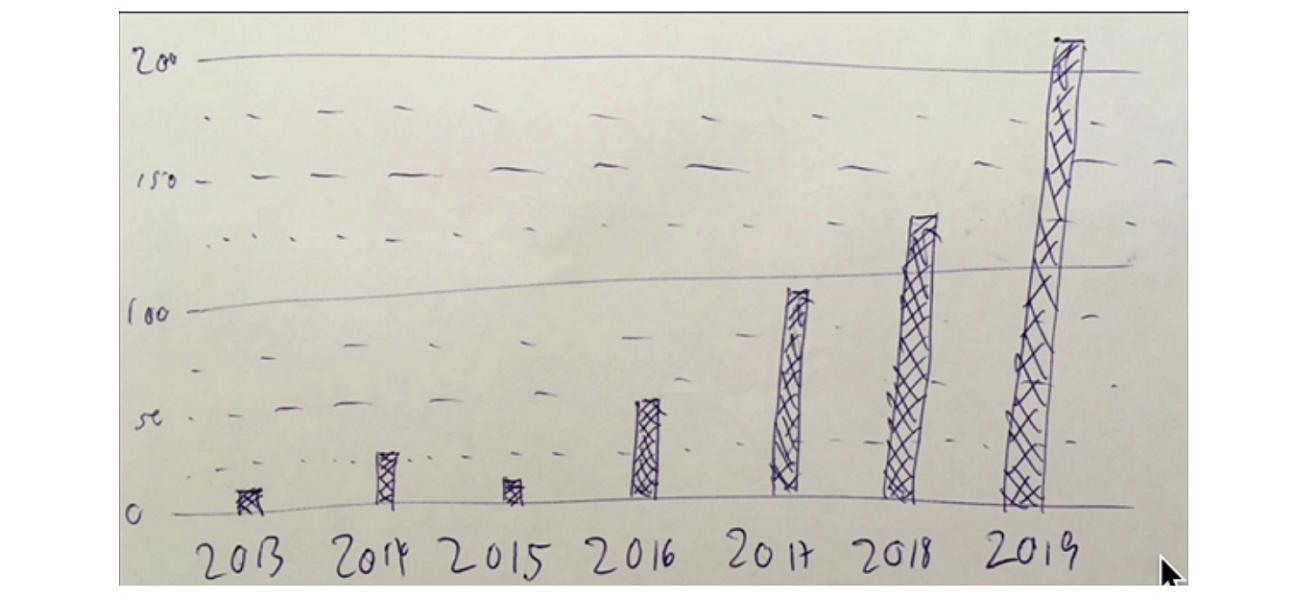
One of the fastest growing sub-fields in the deep learning and artificial intelligence community is reinforcement learning (RL), particularly RL with deep function approximation (“deep RL”). NeurIPS itself has seen exponential growth in the number of accepted RL papers (see figure below for a practitioner’s approximation). Currently, the pressing issue of deep RL is sample efficiency: how do we efficiently train RL agents with limited training data and permit them to 1) perform, and 2) generalize well at test time? Researchers are pursuing several approaches:
- Adding structural priors to aid the learning process has been shown to push empirical results on classical benchmarks like the Atari games. Hierarchical RL (HRL), as its name entails, decomposes an agent’s overall policy into several hierarchies. Popular HRL abstractions like the Options framework by Sutton et al. and HIRO by Nachum et al. have been shown to be highly sample-efficient compared to non-HRL baselines. Why Does Hierarchy (Sometimes) Work So Well in Reinforcement Learning? by Nachum et al. evaluates several hypotheses related to HRL and empirically determines that the bulk of HRL’s success comes from its modified exploration policy–a result of higher-level policies that explore across multiple temporally connected environment steps.
- Another approach to more data-efficient RL focuses on improving how rewards are credited to particular actions in a sampled trajectory during training. The classical formulation of RL implicitly uses temporality and time to credit rewards to actions: actions taken closer to a reward signal will receive a higher weight. Hindsight Credit Assignment by Harutyunyan et al. uses the likelihood of actions resulting in outcomes through hindsight analysis to assign importance weights to the respective actions.
- Model-based RL has shown itself to be empirically more data-efficient than model-free RL, although not without caveats. Researchers have achieved groundbreaking SOTA results using model-based RL, such as AlphaZero by Silver et al., on challenging games like Chess and Shogi. At NeurIPS, the same group of researchers from DeepMind unveiled MuZero by Schrittwieser et al., an extension to AlphaZero where the rules of the game are learned rather than hard-coded in the model. This permits MuZero to be applied towards Chess, Go, and Shogi, as well as the entire Atari games suite, without additional human input on the games’ rules, while maintaining the SOTA performance AlphaZero previously achieved.
Meta-Learning in Reinforcement Learning
Meta-learning research aims to improve the process of learning how to learn. Concretely, many approaches, such as MAML by Finn et al. and PEARL by Rakelly et al., learn a model on a set of related learning tasks, such that the model may generalize to other, similar tasks with only a small number of training examples at inference time. That being said, several researchers are working to apply meta-learning to reinforcement learning (meta-RL) to try to achieve better data-efficiency and generalization.
- Following the inner-outer loop paradigm, Guided Meta-Policy Search by Mendonca et al. performs data-efficient RL independently per task in the inner loop, then distills the policies via supervised imitation learning in the outer loop. The researchers combine both RL and supervised learning in a framework that is more sample-efficient than competing baselines.
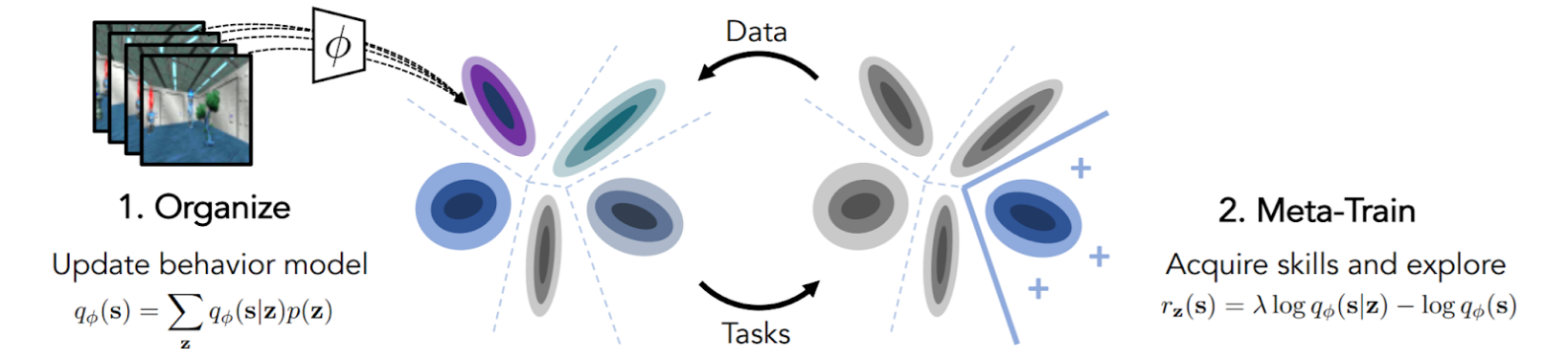
- Deciding on a good distribution of learning tasks to employ in meta-RL usually requires a strong human prior. Unsupervised Curricula for Visual Meta-Reinforcement Learning by Jabri et al. (CARML) attempts to remove this constraint by learning a useful task distribution via variational expectation-maximization of the mutual information between the learner’s data distribution and the distribution induced by a latent task variable.
Although meta-learning provides hope for learning how to generalize in difficult-to-design-by-hand situations, one major drawback of MAML is that it differentiates through the inner loop, therefore when the inner loop uses more iterations, there is memory issue and the dependency of the inner loop solution on the meta parameter becomes weak. In addition, it is also hard to adopt more complicated optimization algorithms, such as black-box optimization, ADAM, second-order Hessian-Free algorithm etc. The idea of Meta-Learning with Implicit Gradients (iMAML) is that the solution of an optimization algorithm doesn’t depend so much on how it is reached, but more on the problem setup and the loss function etc., therefore one can derive the meta-gradient by solving some quadratic optimization problem. A further development in ICLR this year makes the algorithm even more flexible and stable.
Causal Inference
The aim of causal inference is to determine a causal relationship between a covariate x and response y. Determining this causal relationship is oftentimes challenging due to the presence of confounders, or variables that affect both x and y. Unfortunately, we often don’t have access to observations of confounding variables, which makes inference challenging or impossible. However, by identifying instrumental variables z (variables which affect y only through x), we can still identify the causal relationship. The classic approach to solving this problem is known as two stage least squares (2SLS), and assumes a linear relationship between x, y, z and confounder. In this case, the structural function given by y=h(x)+e is linear. Performing linear regression of y on x suffers from omitted variable bias, but by instead regressing y on the E[x|z] we obtain an unbiased estimate of the structural function.
In Kernel Instrumental Variable Regression, the authors generalize the classic 2SLS approach to handle a nonlinear relationship between x,y and z. In Kernel Instrumental Variables, we embed x into a Reproducing Kernel Hilbert Space (RKHS) through the feature map psi. We compute a conditional mean embedding corresponding to the expected value of psi given instrumental variables, by embedding the instrument into an RKHS through feature map phi. By applying the kernel trick twice, we can perform the kernel ridge regression of response onto expected value of psi given instrument.
Kernel IV is closely related to Sieve IV, another nonlinear generalization of 2SLS. Sieve IV is analogous to Kernel IV, except that feature maps psi and phi correspond to a finite dictionary of nonlinear basis functions. The authors also show favorable improvements over Deep IV in the sigmoid design experiment. In Deep IV, stage 1 corresponds to estimation of a conditional density f(x|z) which is parametrized by a neural network. The conditional density is used in stage 2 to minimize the squared error between loss and expected value of h given z, where h corresponds to another neural network, and expectations are estimated by sampling from the stage 1 density.
Black in AI Workshop
This year, Two Sigma joined many of the leading names in AI and ML in sponsoring the Black in AI Workshop at NeurIPS. This workshop was designed to bring together Black researchers from around the world to present their work in all areas of machine learning as well as interdisciplinary applications, with a focus on the developing world. Through the support of sponsors, the workshop was able to provide travel grants and visa support to dozens of researchers who would otherwise not have been able to attend NeurIPS.
One of the most interesting posters at the workshop was Ramon Vilarino’s work on location and racial bias in credit scoring in Brazil. Ramon recently completed his undergraduate degree in Physics in Brazil and interned at Experian’s data science lab in Sao Paulo. Without the support of Black in AI, Ramon likely would not have had a chance to attend NeurIPS.
In his work, Ramon built a predictive model for credit scores using a wide variety of features. He then applied SHAP to determine what features were driving his model’s prediction. What he found was that the first three digits of a person’s postal code were highly predictive of their credit score. This isn’t entirely unintuitive. But he didn’t stop there.
As we often see in our own analysis, real-world data sets tend to have all kinds of correlated and proxy features. The original data set did not include any features describing race. However, replacing the highly predictive postal code feature with census data indicating the percent of non-white residents in the region covered by the postal code produced an essentially identical model.
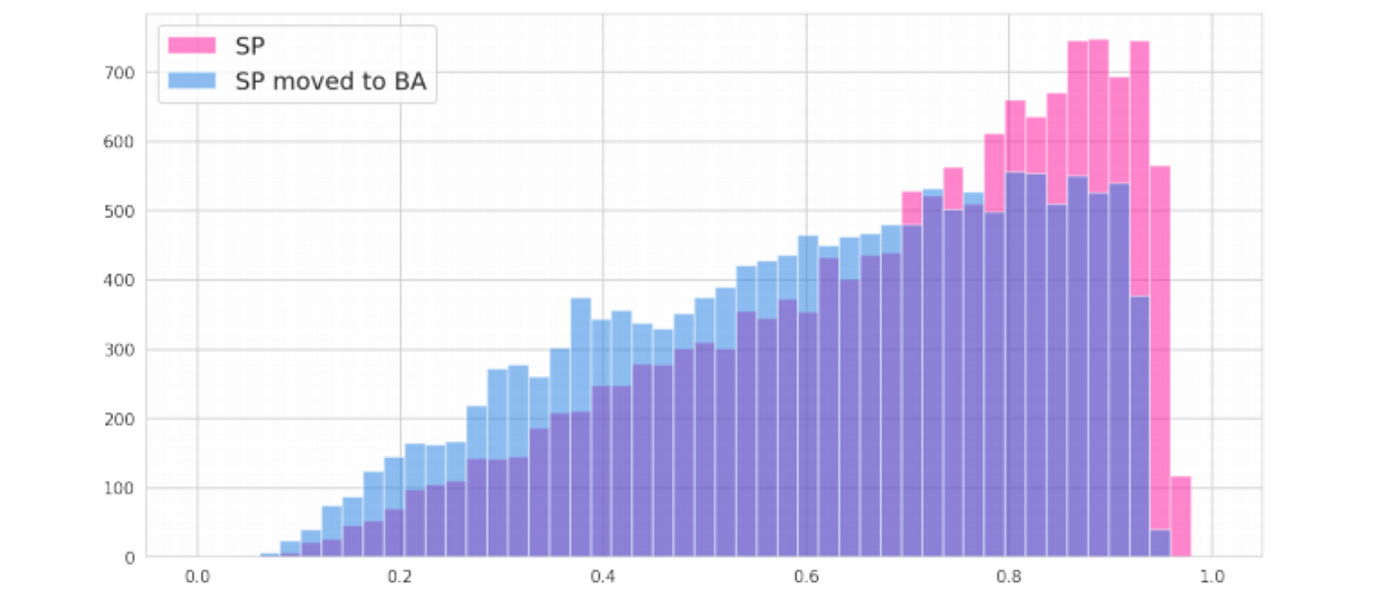
Taking this analysis further, Ramon constructed counterfactual scenarios where he moved individuals from areas of low non-white population to areas of high non-white population. He changed no other features about the individuals, but in 99.85% of cases their credit scores went down simply by moving them.
Moving back up to a higher level, this work is representative of an important class of analysis that looks at the interaction between ML and social systems it is applied to. It is increasingly apparent, for example, that rather than erasing past biases, ML models can reinforce them, while adding a veil of scientific impartiality. This is a theme in the work of Princeton’s Ruha Benjamin, who delivered a powerful keynote at the Black in AI dinner. Ramon and Ruha are now collaborating to extend this work to other domains.
Robotics
The field of robotics has seen tremendous technological advancement in recent years, as reinforcement learning algorithms have been refined to become more data-efficient than their predecessors. Many of these advances are also relevant even to machine learning researchers who specialize in other fields.

A significant challenge in applying reinforcement learning approaches to robotics is transitioning from simulated to real environments (sim2real). Some researchers and practitioners choose to avoid simulation altogether and perform RL on real robotic equipment, but data efficiency becomes the bottleneck as real environment steps take magnitudes longer to execute.
- Solving Rubik’s Cube with a Robot Hand by OpenAI was able to overcome sim2real challenges by Automatic Domain Randomization (ADR). During training in simulation, certain knobs of the environment are randomly perturbed periodically to encourage the agent to learn a policy robust to potential nuances in a real environment.

- Learning to Control Self-Assembling Morphologies: A Study of Generalization via Modularity by Pathak et al investigated an evolutionary approach to a variety of control tasks that are fundamental to robotics movement. In simulation, the co-evolution strategy where primitive limbs may self-assemble to form larger composite limbs was able to achieve progress in tasks such as standing up and locomotion that the monolithic-equivalent policies were unable to match.


